Table of Contents
This article in the Rspotify series describes my journey of basically rewriting the entirety of this Rust library; around 13 months of work (in my free time), starting at September 2020, up until October 2021. I think this has given me enough experience for an article regarding API design on Rust, and perhaps those who attempt the same in the future can take some ideas and save time. Specially considering how much I’ve gone in circles and how much time I’ve “wasted” implementing things that ended up being discarded.
The story
If you don’t care about RSpotify’s specific story, you can jump to the “Making the API HTTP-client agnostic” section, but I think knowing a bit the motives for this rewrite is interesting for other open source maintainers in the same situation as me. This all started when I wanted to use a Rust Spotify API wrapper for one of my projects at that time, Vidify. I went to crates.io and looked for “Spotify”, and all I found was rspotify (the most popular one), aspotify (an asynchronous-only alternative), and a bunch of other outdated or incomplete libraries.
The author of aspotify had made a brand-new library from scratch, because as he commented in its release, “[rspotify’s] API in general I found hard to use and confusing”. Honestly, depending on the state of the original library this is the easiest choice because you don’t have to worry about backwards compatibility or old code.
A year back I had also helped with the first steps of tekore, an alternative to spotipy, the most popular Spotify library for Python out there. The problem was that back then, Paul, spotipy’s creator and maintainer, was absent, and the library really needed a push to upgrade from Python 2 and improve the overall interface and user-friendliness, which had become pretty poor.
A few devs, including Felix, tried to start from scratch. Felix was the most dedicated, and Paul eventually granted him permissions to upload new spotipy releases, meaning that he could rewrite the entire thing under the same name, and upload it to PyPi (Python’s official third-party repositories) if he wanted to. The problem was that spotipy had a good amount of users by that point. A couple of them ended up stopping Felix from completely breaking backward compatibility, so he made it into a brand-new library instead and left the maintainance tasks to the new devs in charge. Tekore still is, in my very biased opinion and at the time of this writing, a much nicer to use library than spotipy. But it has taken a lot of time to get a user base starting from scratch, and it’s still not as popular as spotipy by far.
Having gone through this, I also wanted to see if it would be possible to give RSpotify a face wash without anyone complaining. RSpotify was still in beta – version 0.10 – so you can’t expect to have a stable API, but that’s far from a full rewrite. At the very least I wanted to talk with Ramsay, the original RSpotify developer, and see what his thoughts were. I proposed some big changes like rewriting the blocking module and Kestrer wrote up an issue with ~80 issues he had found when using the library.
I think it’s fair to release the new version 0.11 as such, rather than as a new library, for the following reasons:
- Ramsay, the author, also wanted to help.
- The fundamentals of the library would remain the same: being the most user-friendly feature-full library for the Spotify API.
- It was considered a necessary evil. In my opinion, the library was doomed without a big rewrite. Otherwise, it’d eventually become really hard to maintain and work with. I admit that said breaking changes could’ve been smaller, but I thought that, while I’m at it, I might as well make it as close as possible to a perfect Rust interface.
Also, note that I am in no way associated with Spotify (though open to offers :P). I’m just a Computer Science student whose sole goal was to use Rust for a non-trivial case, from start to finish. I was somewhat experienced with the Spotify API, so I decided RSpotify was a good choice.
Now that most of the stuff I talk about in this article is finished, you can read about the changes in detail in the CHANGELOG. The following sections will talk about what I learned about API Design, and some tips for those writing one in Rust.
Making the API HTTP-client agnostic
RSpotify is now HTTP-client agnostic, which means that it can work with whichever HTTP library the user configures without adding much overhead. For now, we support ureq and reqwest[1]. The non-trivial part about this is that the HTTP client can be either blocking (ureq) or asynchronous (reqwest).
While it’s fully implemented in the new version, it’s the only part that isn’t finished yet and that’s subject to change. This has to do with the way we support both async and sync HTTP clients under the same trait. In order to have a common interface for both kinds of programming, we use the maybe_async crate, which lets us switch between them with a feature.
The trait used as a base for any HTTP client is implemented with async. That way, if the maybe_async/is_sync feature is disabled in the Cargo.toml, the trait and its implementations remain the same, and if it’s enabled, all the occurrences of async and .await are removed. It’s also possible to add special cases where removing async/.await isn’t enough. This works perfectly, but unfortunately breaks a rule in Cargo’s feature system: features must be strictly additive, and maybe_async’s feature is a toggle – you can’t have both a sync and an async client at the same time.
Since we don’t follow that rule, those who depend on RSpotify with both async and sync (directly or indirectly) won’t be able to compile their project. I won’t get into much detail because I’m writing an entire separate post dedicated for this issue that I’ll publish once this whole ordeal is fixed. We’re keeping track of it in #221 for now, for those who want to learn more.
For now, I’ll just explain how it works for clients of the same type: either synchronous or asynchronous. Since the usage for an HTTP client in an API is often very basic, i.e., you only need to make requests and get the results, we can cover its usage under a single interface. For example:
pub trait HttpClient: Send + Default {
type Error;
fn get(
&self,
url: &str,
headers: Option<&Headers>,
payload: &Query,
) -> Result<String, Self::Error>;
fn post(
&self,
url: &str,
headers: Option<&Headers>,
payload: &Value,
) -> Result<String, Self::Error>;
// etc
}Then, we can add an implementation for each of our supported clients:
pub struct UreqClient {}
impl HttpClient for UreqClient {
type Error = ureq::Transport;
#[inline]
fn get(
&self,
url: &str,
headers: Option<&Headers>,
payload: &Query,
) -> Result<String, Self::Error> {
let request = ureq::get(url);
let sender = |mut req: Request| {
for (key, val) in payload.iter() {
req = req.query(key, val)
}
req.call()
};
self.request(request, headers, sender) // Internal more complex handler
}
// etc
}And we can finally make our client generic over its internal HTTP client:
pub struct Spotify<Http: HttpClient> {
http: Http,
// etc
}
impl<Http: HttpClient> Spotify<Http> {
pub fn endpoint(&self) -> String {
let headers = todo!();
let payload = todo!();
self.http.get("/some/endpoint", headers, payload)
}
}Beware that this introduces a good amount of additional complexity which is probably unnecessary for your own API wrapper. But this was definitely something interesting for RSpotify: some crates that already depend on us like ncspot or spotifyd are blocking, and others like spotify-tui use async. I thought I might as well try, and I’ve finally figured out how to make it work, even for both async and sync.
We implement all of this in the crate rspotify-http, which I plan on moving into a separate crate for the whole community to use once it’s working as I want it to. I think this is a pretty neat feature for an API client that will hopefully become easier to implement in the future (and first of all work properly).
Finding a more robust architecture
Another key refactor I worked on for RSpotify was its architecture. The Spotify API in particular has multiple authorization methods that give you access to a different set of endpoints. For example, if you’re using client credentials (the most basic one), then you can’t access an endpoint to modify the user’s data; you need OAuth information. This used to work with the builder pattern, following this structure (though not exactly the same):
// OAuth information
let oauth = SpotifyOAuth::default()
.redirect_uri("http://localhost:8888/callback")
.scope("user-modify-playback-state")
.build()
.unwrap();
// Basic information
let creds = SpotifyClientCredentials::default()
.client_id("this-is-my-client-id")
.client_secret("this-is-my-client-secret")
.build()
.unwrap();
// Obtaining the access token
let token = get_token(&mut oauth).unwrap();
// The client itself
let spotify = Spotify::default()
.client_credentials_manager(creds)
.token_info(token)
.build()
.unwrap();
// Performing a request
spotify.seek_track(25000, None).unwrap();I wanted something more tailored towards our specific application. I think the builder pattern is great, but it might become too verbose or confusing:
- Do we really need it for
Credentials, which always takes the same two parameters? - Which authorization method are we using above again? Currently, it’s possible to call
seek_trackafter having followed an authorization process that doesn’t give access to it. And since we’re mixing all of them under the same client it quickly becomes a mess, having manyOption<T>fields that are onlySomefor specific authorization methods. So, what if we have a Spotify client for each authorization method? - Wouldn’t it be nice to have some type safety, too? The
unwraphurts my eyes.
After removing the builder pattern and being more explicit about the authorization method that’s being used, this is more or less what we get:
// OAuth information
let oauth = OAuth::new("http://localhost:8888/callback", "user-read-currently-playing");
// Basic information
let creds = Credentials::new("my-client-id", "my-client-secret");
// The client itself, now clearly with the "authorization code" method
let mut spotify = AuthCodeSpotify::new(creds, oauth);
// Obtaining the access token
spotify.prompt_for_token().unwrap();
// Performing a request
spotify.seek_track(25000, None).unwrap();And if the user wants something more advanced, they can always write this:
let oauth = OAuth {
redirect_uri: "http://localhost:8888/callback",
state: generate_random_string(16, alphabets::ALPHANUM),
scopes: "user-read-currently-playing",
..Default::default()
};It’s sufficient to use the regular initialization pattern for this case because we don’t even need validation. If we did, we could always just add a few setters or checks before its usage and we’re done. Ask yourself: do you really need the builder pattern? In this case we certainly didn’t.
The most complicated part of the refactor is having a client for each authorization method, and making sure the user can only call those endpoints they have access to. There are many ways to approach this, I just had to decide which one was the best. I gave this a lot of thought[2][3].
Having multiple clients seems trivial with inheritance, with a base from which they can extend. In Rust, we could follow the typical “composition over inheritance” principle:
pub struct EndpointsBase {
http: Rc<Http> // Shared with the rest of the endpoints
}
impl EndpointsBase {
pub fn endpoint1(&self) { self.http.get("/endpoint1") }
pub fn endpoint2(&self) { self.http.get("/endpoint2") }
// etc
}
pub struct EndpointsOAuth {
token: Token,
http: Rc<Http>
}
impl EndpointsOAuth {
pub fn endpoint3(&self) { self.http.get_oauth("/endpoint3", self.token) }
pub fn endpoint4(&self) { self.http.get_oauth("/endpoint4", self.token) }
// etc
}
pub struct AuthCodeSpotify(EndpointsBase, EndpointsOAuth);
impl AuthCodeSpotify {
pub fn authenticate(&self) { /* ... */ }
pub fn base(&self) -> &EndpointsBase { &self.0 }
pub fn oauth(&self) -> &EndpointsOAuth { &self.1 }
}The user can then write spotify.base().endpoint1() or spotify.oauth().endpoint3() to access the endpoints in their different groups. However, all of them have to share a single HTTP client and other information such as the config or the token, so we have to use something like Rc. We can improve this by taking ideas from aspotify, another popular crate for the Spotify API, which groups up the endpoints by categories. Their endpoint groups take a reference to the client itself instead, which is pretty neat and works just as well. Here is a simplified version of this Rust Playground:
pub trait Spotify {
fn get_http(&self) -> &Http;
fn get_token(&self) -> &Token;
}
pub struct EndpointsBase<'a, S: Spotify>(&'a S);
impl<S: Spotify> EndpointsBase<'_, S> {
pub fn endpoint1(&self) { self.0.get_http().get("/endpoint1") }
pub fn endpoint2(&self) { self.0.get_http().get("/endpoint2") }
// etc
}
pub struct EndpointsOAuth<'a, S: Spotify>(&'a S);
impl<S: Spotify> EndpointsOAuth<'_, S> {
pub fn endpoint3(&self) { self.0.get_http().get_oauth("/endpoint3", self.0.get_token()) }
pub fn endpoint4(&self) { self.0.get_http().get_oauth("/endpoint4", self.0.get_token()) }
// etc
}
pub struct AuthCodeSpotify {
pub http: Http,
pub token: Token
}
impl Spotify for AuthCodeSpotify {
fn get_http(&self) -> &Http { &self.http }
fn get_token(&self) -> &Token { &self.token }
}
impl AuthCodeSpotify {
pub fn authenticate(&self) { /* ... */ }
pub fn base(&self) -> EndpointsBase<'_, Self> { EndpointsBase(self) }
pub fn oauth(&self) -> EndpointsOAuth<'_, Self> { EndpointsOAuth(self) }
}However, you might think using just spotify.endpoint1() instead of spotify.base().endpoint1() is more suitable for your particular API client. The only way to do that would be to delegate every single endpoint manually into the main client. Some people use Deref and DerefMut in order to automatically do it, but that’s a common anti-pattern[4].
I tried different approaches, and my favorite ended up being a trait-based interface. All you need is a couple traits with the endpoint implementations, which require a getter to the HTTP client or similars. Here is a simplified version of this Rust Playground:
pub trait EndpointsBase {
fn get_http(&self) -> &Http;
fn endpoint1(&self) { self.get_http().get("/endpoint1") }
fn endpoint2(&self) { self.get_http().get("/endpoint2") }
// etc
}
pub trait EndpointsOAuth: EndpointsBase {
fn get_token(&self) -> &Token;
fn endpoint3(&self) { self.get_http().get_oauth("/endpoint3", self.get_token()) }
fn endpoint4(&self) { self.get_http().get_oauth("/endpoint4", self.get_token()) }
// etc
}
pub struct AuthCodeSpotify(Http, Token);
impl AuthCodeSpotify {
pub fn authenticate(&self) { /* ... */ }
}
impl EndpointsBase for AuthCodeSpotify {
fn get_http(&self) -> &Http { &self.0 }
}
impl EndpointsOAuth for AuthCodeSpotify {
fn get_token(&self) -> &Token { &self.1 }
}This way, as long as the user has these traits in scope, they can access the endpoints with just spotify.endpoint1(). We can make that easier by including a prelude in the library with these traits, so that all the user has to do is use rspotify::prelude::*. Another big advantage this provides is that it’s extremely flexible. The user can declare their own client and implement its internal functionality themselves, while still having access to the endpoints, which is the boring task that probably doesn’t need customization. And even if they wanted to, they could just override the trait implementation.
The main issue with the trait-based solution is that you can’t use -> impl Trait in trait methods as of Rust 1.55[5]. We unfortunately need these, specially with asynchronous clients, because async trait methods are -> impl Future after all. For now, we can work around it by erasing the types with the async-trait crate. Supposedly, this will be temporary until GATs are implemented, which isn’t too far off[6].
Both of these solutions also make it hard to have private functions in the base client, because the shared parts are in a trait. We don’t really want the user to have access to the methods get or get_oauth. It’s defined in the client/trait because it’s useful for every client, but for the end user it’s just noise in the documentation. This isn’t that much of a big deal because you can just declare the item with #[doc(hidden)] so that it doesn’t appear in the documentation.
So yeah, there are no perfect solutions, but these are two of the best ones I could find. The choice is up to the designer of the library and their needs. Having multiple clients let us implement PKCE Authentication for RSpotify quite easily, so it’s worth it in the end anyway. Our final architecture looks like this (diagram by Ramsay):
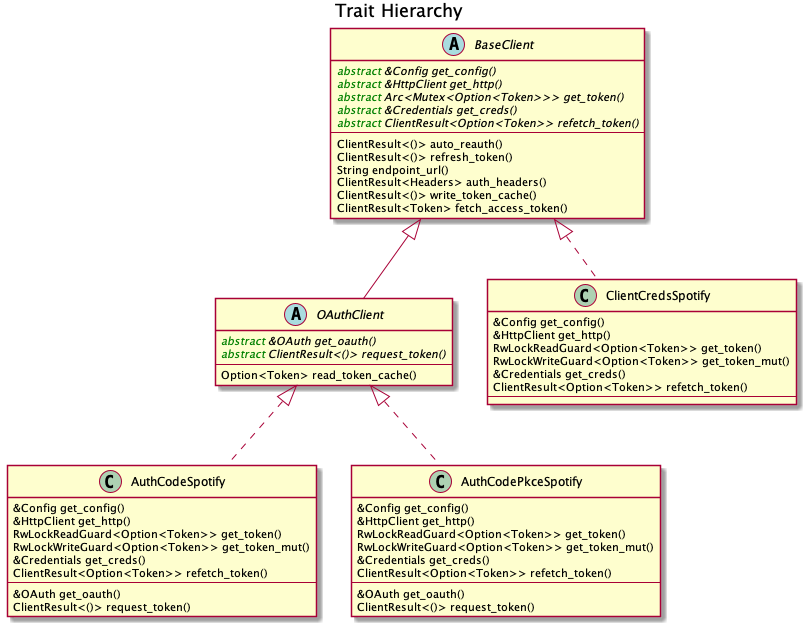
Configuration
Runtime over compile-time
There are a few parts of the Spotify client that can be customized by the user. Previously, these were just fields of the main client, but since we now have multiple clients, it might be worth moving into a separate struct to avoid duplication.
Anyhow, one of our fails was attempting to use features instead of the Config struct for configuration, on the assumption that features would be more performant. Which one is faster?
if self.config.cached_token {
println!("Saving cache token to the file!");
}
#[cfg(feature = "cached_token")]
{
println!("Saving cache token to the file!");
}Turns out that both of these are usually compiled to the same machine code anyway. Since self.config.cached_token is most times specified as a constant, optimizing it away is one of the more basic tasks a compiler can do. Features are drastically less flexible and harder to use than runtime variables, so before introducing one you should really think about it. Apart from the fact that you obviously can’t use features at runtime (which is a possible use-case here), they are applied globally, so you can’t have two different clients, one with cached tokens and another without them. In order to take this decision I actually wrote an entire article about it, so check it out if you want more details.
Even though it’s basic, I keep forgetting about this: don’t get obsessed with performance. As you add new features to the crate, it’s completely natural that some overheads are introduced here and there. And even then, they might not even be noticeable. First of all get that new feature working. Then, measure the real effect on performance. And finally, if it’s more than you expected, then actually think about optimizing it.
One correct usage would be our new cli feature. We have some utilities for command-line programs, such as prompting for the user’s credentials. However, not everyone needs these, such as servers, and it introduced the webbrowser dependency and a few unnecessary functions. So we decided to move this into a separate feature for those interested, which is disabled by default.
Sane defaults
On the topic of configuration, it’s important to have sane defaults as well. This is highly subjective, but I prefer to do as little as possible under the hood without the user knowing about it. When initializing a client we used to automatically try to read from the environment variables. If that didn’t work then we tried to use the default values or we just panicked in the builder:
let creds = SpotifyClientCredentials::default() // this reads the env variables
.client_id("this-is-my-client-id")
.client_secret("this-is-my-client-secret")
.build()
.unwrap();This is a pretty useful feature, but we can’t be sure the writer/reader of the code knows about it, and it could potentially cause unintended behaviour. Instead, we can just have a default method that does nothing special, which is what the user would expect, and also from_env, which explicitly tells us what it does:
let creds = SpotifyClientCredentials::from_env() // this reads the env variables
.client_id("this-is-my-client-id")
.client_secret("this-is-my-client-secret")
.build()
.unwrap();Flexibility
Taking borrowed/generic parameters
Friendly reminder: generally, it’s better to take a &str than a String in a function[7][8]. The same thing applies to the owned type Vec<T>; it’s probably a better idea to take a &[T] instead, or the even more fancy impl IntoIterator<Item = T>. The last option makes it possible to pass iterators to the function without requiring a collect, which not only is more user-friendly, but also avoids a memory allocation. Its only downside is that the function signatures become a bit uglier, and all the consequences of using generics. Either of these options are fine, really, so it’s up to you.
Optional parameters
Similarly, if the functions in your library frequently include optional parameters (i.e., of type Option<T>), you might want to consider other ways to handle them. In our case, we were using generics with Into<Option<T>> in order to not have to wrap the parameters in Some when passing them to the function, but it wasn’t consistent. We finally agreed that using plain Option<T> was good enough because it simplifies the function definition in the docs and it’s less magic[9]. But the important part is that we made it consistent; the decision itself between Into<Option<T>> or Option<T> wasn’t that important. After doing research about this topic, I wrote up an article with more details here, in case you want to learn more.
Splitting up into multiple crates
Another cool idea that promotes flexibility is separating the wrapper into multiple crates. In RSpotify, we now have a total of four of them (credits to Ramsay for the diagram):
rspotify-http: the multi-HTTP client abstraction, which I plan on making more generic and moving into a separate crate for everyone to use[10]rspotify-macros: a small crate with macrosrspotify-model: the full model for the RSpotify craterspotify: the implementation of the clients
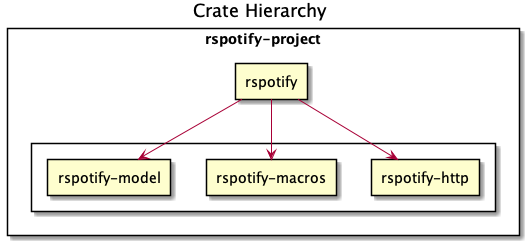
The most important one here is splitting up the wrapper into the model and the clients. The model is generic enough that it can be used by any client, even outside RSpotify. Some users have to implement their own custom clients for different reasons, and pulling our model helps to avoid lots of complexity and maintainance work[11]. It can also be shared with other public crates, such as aspotify, and join forces in keeping the model up to date[12].
Documentation
Introducing how to use the crate
This might be obvious to some, but it isn’t enough to document every single public item in your library. You also have to introduce the user how to work with it in the top-level documentation. Some ideas:
- List the goals, current and future features of the crate, and things you don’t plan working on. Perhaps also add a comparison with similar crates; these are usually super helpful.
- Write a small getting started guide, explaining the most important items in the crate and what they do.
- Add some notes about the architecture of your crate. This is specially useul to those who want to contribute. For RSpotify, Ramsay created the diagrams included in this article, and added more details in the README.
- Explain the Cargo features in your crate and how to use them.
- Make sure you have a few examples working. It’s the easiest way to get started, in my opinion.
Helping users upgrade
Since this change was going to break so much code, I wanted to make sure that the upgrade is as less painful as possible. This can be achieved in many ways:
- Make sure you prove why these breaking changes are actually necessary. It will feel like less of a waste of time to the user.
- Include a changelog, either as an indepent file, or in the release notes. In RSpotify, we make habit of adding a new line to the changelog for every release that includes a new feature or breaking changes. To be honest, in our case it’s turned out quite messy because we had so many changes, but in a regular update it should be nicer to read.
- It might be a good idea to create an issue in your repository where you provide help directly to those who try to upgrade and have problems with it.
Macros
Macros in Rust are pretty cool! But you don’t want to overdo them either. In rspotify we frequently had to build hashmaps or JSON objects; at least once per endpoint. Some of the parameters in the endpoints were mandatory, and others optional (passed as an Option):
let mut params = Query::with_capacity(3);
params.insert("ids", ids);
params.insert("limit", limit.to_string());
if let Some(ref market) = market {
params.insert("market", market.as_ref());
}I first tried to simplify this by using macros to their full strength, so my initial attempts looked like this:
let params = build_map! {
ids,
limit => limit.to_string(),
optional market => market.as_ref(),
};Or this:
let params = build_map! {
ids,
limit => limit.to_string(),
Some(market) => market.as_ref()
};Yes, they are very concise and we remove a lot of boilerplate, but they’re bad for two reasons:
- There’s too much magic going on:
- They turn the
ids/limit/marketidentifiers into a string withstringify!and use that as the key for the hashmap insertion. - In the expression to the right of an optional parameter, its value isn’t treated as an
Optionanymore; there’s a hiddenif let Some(market).
- They turn the
- The syntax is weird. In order to understand them correctly, you’d probably have to look up their documentation and read it first.
The final design still reduces the boilerplate needed in each endpoint considerably, but there’s no magic going on. It’s basically the same as a regular hashmap builder macro like you’d find on maplit, and the macro doesn’t hide anything:
let params = build_map! {
"ids": ids,
"limit": limit.to_string(),
optional "market": market.map(|x| x.as_ref()),
};Anyhow, we might remove it in the future, since this syntax will soon work as well[13]:
HashMap::from([
(k1, v1),
(k2, v2)
]);Other goodies
Some new features we added to RSpotify that might be of interest specifically for other web API wrappers:
Cached and self-refreshing tokens
Cached tokens are automatically saved into a file, encoded for example in JSON, and then attempted to be loaded again when restarting the application.
Before making a request, self-refreshing tokens check if they are expired, and in that case perform the re-authorization process automatically.
Type-safe wrappers for ID types
In the Spotify API, items such as artists or tracks are identified by a unique ID string. The URI is the ID, but prefixed by its type, for example spotify:track:4cOdK2wGLETKBW3PvgPWqT.
Many endpoints previously took the URI parameters as a String. That meant we had to manually check that their type were what we were expecting, and also that they were valid (they’re usually made up of alphanumeric characters).
Instead, we now have an Id trait and structs that implement it, like ArtistId or TrackId, keeping its type known at compile time and also at runtime with dyn Id. If you take a TrackId as a parameter, then you already know its type, and that its contents are valid, so you’re ready to use it.
Automatic pagination
Many API servers have paginated replies for large lists. Instead of sending a huge object, it splits it up into multiple packets, and sends them one by one along with an index to the position in the list. Then, the user can stop requesting them at any time and potentially only end up using a portion of that originally huge object.
In Rust, this can be abstracted away very naturally with iterators in sync programs, and streams for async. The latter can be implemented easily in your crate thanks to async_stream.
Simplify wrapper model objects
Due to how JSON works, sometimes an object will always have a single field:
{
"many_artists": [
{
// ..
},
// ...
]
}In that case, instead of just deserializing that object with serde and returning it to the user, you can just return that one field in the object:
#[derive(Deserialize)]
struct ArtistCollection {
many_artists: Vec<Artists>
}
// Before
fn endpoint() -> Result<ArtistCollection> {
let response = request();
serde_json::from_str(response)
}
// After
fn endpoint() -> Result<Vec<Artists>> {
let response = request();
serde_json::from_str::<ArtistCollection>(response).map(|x| x.many_artists)
}Measuring the changes
Since this release changed so much stuff and took so long, I wanted to get a detailed comparison between v0.10 and v0.11 for different aspects of the library – not just performance.
The full source for these benchmarks is available at the marioortizmanero/rspotify-bench repository. Note that I had to apply a small patch to the v0.10 version because by now it didn’t work correctly.
Statistics
Some parts of RSpotify can be analyzed statically, such as the lines of code that will need to be maintained, or its number of dependencies. Here’s an example as of October 12, 2021:
| Version | Rust LoC | Dependencies in tree | Dependencies in tree (all features) |
|---|---|---|---|
| 0.10.0 | 11281 | 132 | 141 |
| master | 7525 | 101 | 123 |
The Lines of Code in the old version were quite bloated because of the blocking module, which was a copy-paste of the async client. Still, these were lines that needed to be maintained, so they count just as much. On the other hand, we now have a much more extensive set of tests and new features that add up. In total, we have about 33% less lines to be maintained.
The number of dependencies has decreased both by default and with all the features enabled. We cleaned up a lot of them and tried to keep the defaults leaner. Since the new version adds more features such as PKCE, we even had to add new dependencies like sha2, but it’s still a clear win.
Execution time
The execution benchmarks use Criterion, with a total of 100 iterations on my Dell Vostro 5481 laptop, or more specifically, Intel i5-8265U (8) @ 3.900GHz. The full reports are available in the report directory of each benchmark.
Taking a look at the Criterion reports, it seems that the Spotify API doesn’t intentionally slow down responses when it’s being “spammed”, so it should be fine in that regard:
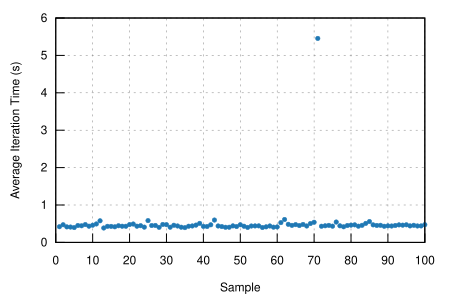
Note that comparing the blocking clients for now is unfair, because instead of using reqwest::blocking, now it’s ureq. Furthermore, the async and sync versions can’t be compared either, since the former requires setting up the tokio runtime and a bunch of other stuff.
The asynchronous clients in both versions should give a rough idea of the actual differences, though you can tell it’s just a quick benchmark, and the results shouldn’t be taken too seriously in the first place. Here’s an example as of October 12, 2021:
| Version | Debug Compilation Time (s) | Release Compilation Time (s) | Benchmarking Time (ms/iter) | Release Binary Size (MB) | Release Stripped Binary Size (MB) |
|---|---|---|---|---|---|
| 0.10, blocking | 72.7 | 126.2 | 271.3 | 9.9 | 4.9 |
| 0.10, async | 72.2 | 115.7 | 428.0 | 11 | 5.2 |
| 0.11, blocking (ureq) | 38.5 | 55.9 | 503.6 | 7.3 | 2.6 |
| 0.11, async (reqwest) | 51.014 | 86.594 | 432.49 | 8.5 | 4.0 |
I also wanted to reflect the compilation time, since it’s a possibility that we have less dependencies, but of larger size. The results show that this isn’t the case, since it takes 29% less time to build in debug mode, and 25% less time in release mode.
In terms of execution time, I didn’t expect it to be any better. Even though the architecture and implementation is cleaner, some of the new features introduce noticeable overhead. For example, now that we have automatically refreshing tokens, the Token has to be saved in an Arc<Mutex<T>>, which means we’re locking and unlocking at least once per request. Still, the difference is negligible: just a 1% increase.
The cleanup and all these dependencies we removed mean that the resulting binary is also smaller, and by a lot: there’s a 23% decrease in its size.
Special thanks
This release has been possible thanks to @ramsayleung, @kstep, @hellbound22, @Qluxzz, @icewind1991, @aramperes, @Sydpy, @arlyon, @flip1995, and @Rigellute.
I’m specially grateful towards Ramsay, who apart from contributing many of the features I listed here, read and reviewed every single one of my issues and pull requests. I’ve learned how important it is to have a second opinon, and someone else who proofreads everything before you merge dumb stuff into master. Note that I did proofread my own ideas and pull requests, but there are some things that you just don’t notice on time, as much as you try to. This is a problem that I think is particularly relevant in open source. I personally had worked on projects alone most of the time, and the difference is huge. I would suggest everyone to try to join forces with at least one more person when working in side projects.
That’s all! I hope this post provided insightful information and that you learned something from it. Remember that you can leave a comment at the bottom in case you want to discuss it.
Lots of love,
Mario
Footnotes
Restructure the authentication process ramsayleung/rspotify#173 ↩︎
Designing a new architecture for RSpotify based on trait inheritance, need opinions - Reddit ↩︎
Is it possible to use
impl Traitas a function’s return type in a trait definition? - StackOverFlow ↩︎Tracking issue for generic associated types (GAT) rust-lang/rust#4426 ↩︎
Pass parameters by reference and use iterators wherever possible ramsayleung/rspotify#206 ↩︎
Use an external HTTP universal interface instead of
rspotify-httpramsayleung/rspotify#234 ↩︎Move model into a separate rspotify-model crate ramsayleung/rspotify#191 ↩︎
Sharing the model with rspotify-model KaiJewson/aspotify#14 ↩︎