Table of Contents
- Benchmarking
- Experiments
- Unimplemented ideas
- More detailed benchmarking
- Investigate wrapper overhead
- Investigate async runtime conflicts
- Benchmark async_ffi
- Improve error reporting
- Reduce error handling boilerplate
- Reduce async boilerplate
- Improve cross-platform support
- Performance impact of panic handling
- Use -Z randomize-layout to find FFI bugs
- Try raw dynamic loading
- Simplify the interface further
- For the long-term future
- Conclusion
- Appendix A: Open Source Contributions
- Appendix B: Other Achievements
Welcome to the final article of this series! Here I’ll showcase some clean-ups and optimizations I may or may not have performed yet, so that our plugin system can get closer to production. I will also run benchmarks for some of these to ensure that the changes are actually worth it.
Benchmarking
Tooling
There are all kinds of ways to measure the performance of a system, and it’s important to take as many of them as possible into account. Here are the ones I used myself:
- Raw metrics: Tremor is able to measure its own raw throughput, latency ranges, or standard deviation. They serve as an overall score and are very easy to compare against eachother.
perf.data: the commandperfmeasures the runtime performance thanks to monitoring capabilities in the Linux kernel. It generates a file with the full execution trace, which can be visualized in multiple ways, including:- Flamegraphs: hierarchical and simple graphs.
perf report: the integrated CLI, which is more detailed but harder to understand.
- High Dynamic Range (HDR) histograms: Tremor’s latency percentiles can be turned into a graph with this site.
There are many other techniques available for benchmarking, though. I wasn’t able to get into lower level performance indicators like cache misses. This part of the project has helped me realize how hard it is to benchmark a program reliably; I would suggest checking out other dedicated learning sources on the topic. You should also tune the process according to your use-case, since it may vary heavily between programs. See “More detailed benchmarking” for more information.
Methodology
My first issue was only having my laptop available for the benchmarks. It’s a decent machine, but it caused greater variance in the results, and it wasn’t very productive, since I had to stop everything I was doing to exclusively run them. The Tremor team helped me out by granting me access to their dedicated benchmarking server; here are the full specs of both machines, for reference:
| Machine | CPU | RAM | Disk | Operating System |
|---|---|---|---|---|
| Laptop (Dell Vostro 5481) | Intel i5-8265U | 16 GB @ 2667 MHz | SSD | Arch Linux, 5.18 kernel, 64 bits |
| Benchmarking Machine | Intel Xeon E-2278G | 32 GB @ 2667 MHz | SSD | Ubuntu 20.04, 5.4 kernel, 64 bits |
I ended up developing a custom script to run all the tests properly:
- It first validates the configuration, including what benchmarks to run and what binaries to compare. It was quite annoying to run into a typo 2 hours into the benchmarks…
- It performs a few warmup rounds before the actual benchmarks. This was specially important when using my laptop, since it started to overheat after the first few rounds, degrading its performance.
One way to ensure the variance isn’t too high is to run the exact same benchmark twice. Here’s a histogram for both machines. Unexpectedly, the server ended up having greater variance with this test, but it was good enough to continue anyway.
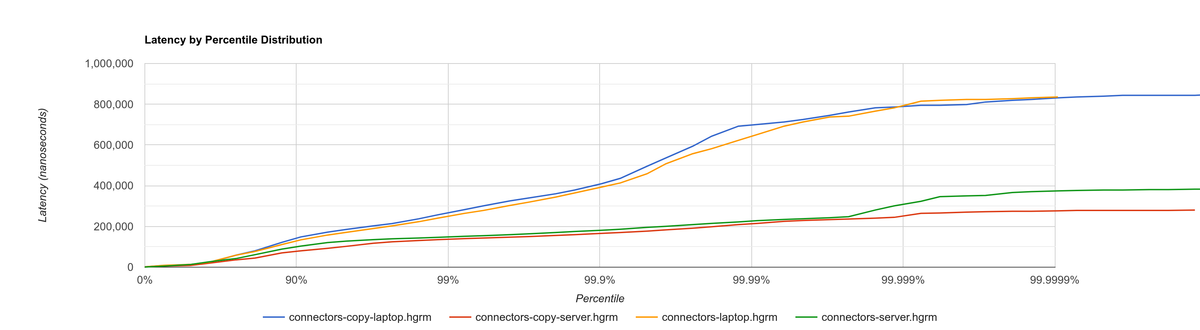
I would strongly recommend anyone to get a separate machine to run benchmarks. Not only will they be more reliable, but also you will be able to continue working while the benchmarks run.
NOTE: The measurements in this article are performed with the new #[repr(C)] interface, but the plugins aren’t actually loaded dynamically yet. This is because, as the planning specifies, we are on a previous step to actually making the plugins external. The final performance will be slightly worse.
Experiments
We can divide the experiments in two categories:
- For tracking: the change is always going to be a good idea, because it may also clean up the code or make it more robust. We just measure its performance impact to report the results and avoid surprises.
- For investigation: the change increases the complexity to explicitly improve performance, so we need to make sure it’s worth our time. This improvement may occur directly with the change, or indirectly by helping to come up with new optimizations.
Benchmarking is only essential in the latter, but I thought it would be a great idea in both cases. That way, I can write up a report like this article, explaining the improvements I worked on.
Type conversions
The most important performance concern in the first version of the plugin system had to do with the issues I had found when trying to convert external types to the C ABI. In short, there was an existing type named Value, which I needed to make FFI-safe for the plugin system. However, it was used throughout the entire codebase, and modifying its definition would’ve required a large amount of unrelated changes for just the first iteration.
My temporary fix was to create the copy PdkValue, and convert to Value and back when going through the FFI boundary. PdkValue was only used for the plugin system, making it quite easy to implement in contrast.
An obvious experiment was to fix this problem properly by making Value FFI-safe and removing PdkValue. Unless the performance degraded considerably, this was always going to be a nice change because it would simplify the code.
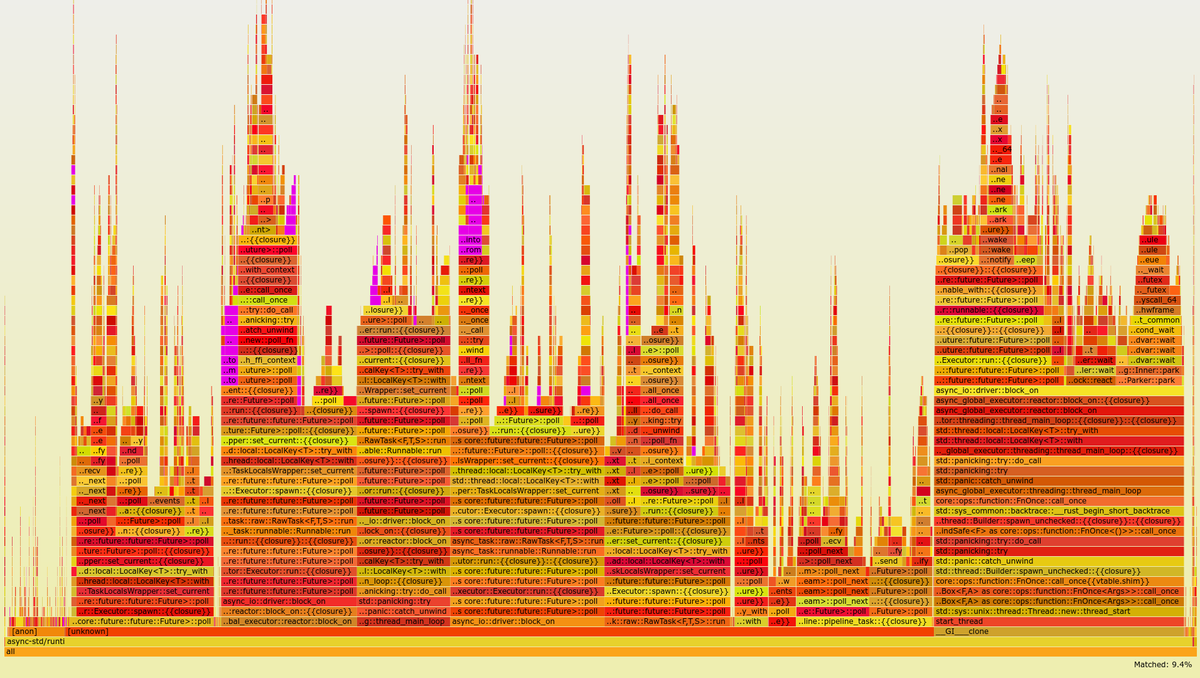
After the fix, I was able to investigate about the impact of these conversions with some flamegraphs:
With both Value and PdkValue (highlighted in pink are the occurrences of From, Into, and FromIterator, which add up to 9.4% of all the calls in the execution):
With a single Value (the conversion calls add up to 5.2% now, and the highlighted parts are much more sparse and harder to notice):
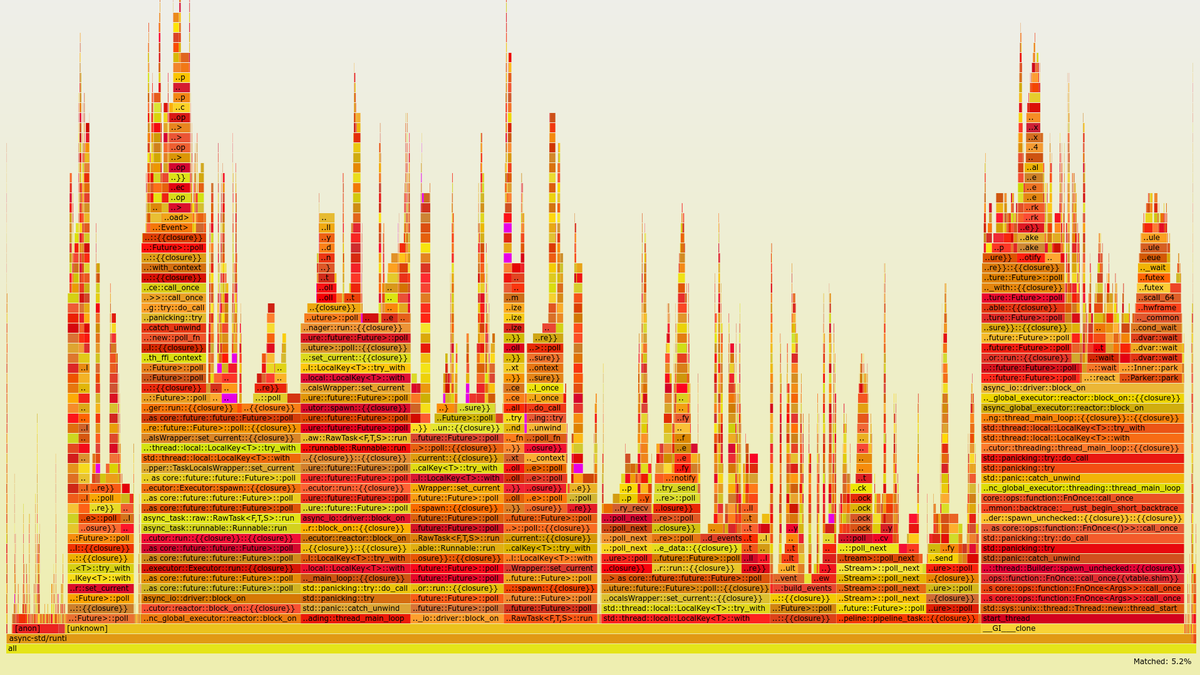
The flamegraphs pointed out that Tremor was spending roughly 4.2% more of its execution time just converting between Value and PdkValue. This metric is tricky, though. Spending less time on type conversions doesn’t mean that the overall program is faster. The percentages are relative to the specific execution, and it’s possible that the rest of the program just got slower in the case of a single Value.
By checking other metrics we discover that this is more or less the case. The histogram shows that while a single Value improves the latency, the overall throughput actually decreases. This compares a version without the plugin system (connectors branch) vs. first version vs. single Value.
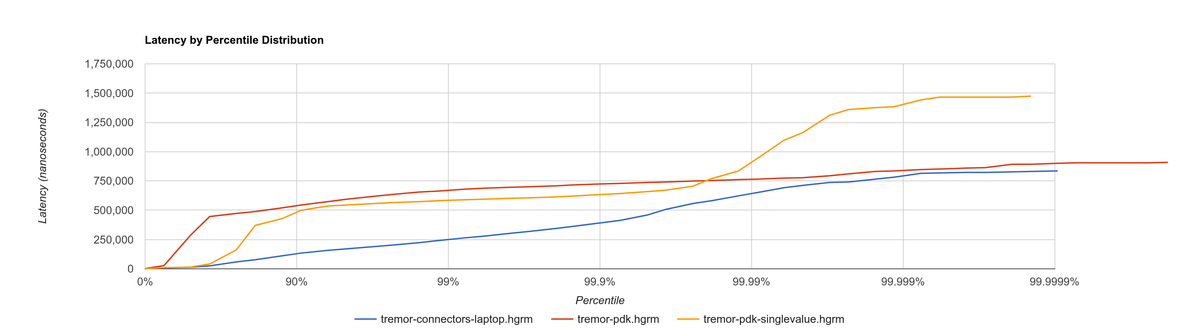
Relative throughput comparison (higher is better):
| No plugin system (%) | With PdkValue (%) |
Single Value (%) |
|---|---|---|
| 100 | 66.67 | 63.74 |
This showcases one of my initial mistakes. My comparison only used the passthrough benchmark, which simply forwards all input events to the output. For a more realistic use-case, I should’ve also tried with other configurations, which may include different payloads or event processing logic. In retrospect, these results should be taken with a grain of salt.
Anyway, it all makes sense to some degree. Converting Value to an FFI-safe type requires using, among others, RHashMap instead of HashMap internally. Tremor’s original HashMap was taken from the halfbrown crate, which was more performant than the standard library version, and even more than abi_stable’s. Converting between types temporarily for the FFI interface might actually be faster than using less performant types everywhere.
Double Box
I later came up with an improvement over the previous section. The HashMap within Value was originally stored inside a Box to reduce the overall size of the enum. In the experiment, I just converted it to a RBox and called it a day:
enum Value {
// ...
- Object(Box<HashMap<String, Value>>),
+ Object(RBox<RHashMap<RString, Value>>),
// ...
}
However, turns out that unlike RString or RCow, RHashMap isn’t a re-implementation of the underlying type. Writing a hash table from scratch is too complex, so the author just made it an opaque type that wraps the standard library version.
Since RHashMap is an opaque type, it was already on the heap internally thanks to another RBox. Thus, the Object variant was boxed twice, which is unnecessary, since the size of RHashMap is already minimal. Having to allocate every hash table twice was probably costly, and fixing this counted as a clean-up, so it was worth trying.
The subsequent benchmarks showed a slight improvement in performance, though I was still only using the passthrough benchmark at this point. I kept the change because it didn’t make much sense to leave the doubly boxed hash table, and because it slightly improved the readability of the code. Here’s the histogram of a double box vs. a single box. Note that this histogram was recorded on the benchmarking server, while the previous one used my laptop. These tests aren’t meant to be compared between different sections.
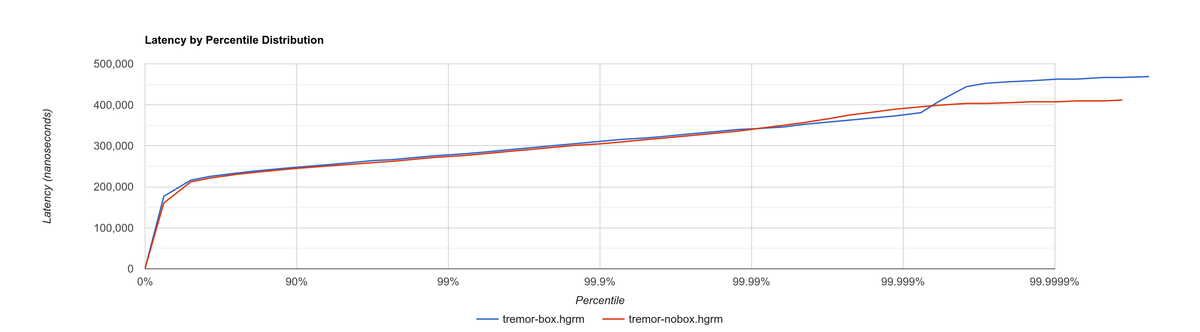
Relative throughput comparison (higher is better):
Double RBox (%) |
Single RBox (%) |
|---|---|
| 100 | 100.82 |
Hash table optimization
Using a single Value improved the ergonomics of the code by sacrificing a bit of efficiency. We could try to fix this regression by creating an FFI-safe wrapper for the original external hash table implementation, which is what I did.
Tremor used halfbrown both because it’s faster for their usecase, and because it has access to lower level functionality. The raw_entry interface is only available on nightly Rust, while halfbrown exports it in its stable version. raw_entry makes it possible to memoize hashes, enabling an optimization in Tremor’s JSON handling.
NOTE: This actually isn’t a great idea in the long term, because raw_entry isn’t going to make it to a stable release[1]. The Rust team is working on a different interface, but it will probably be similar enough that updating our raw_entry usage won’t be too much work.
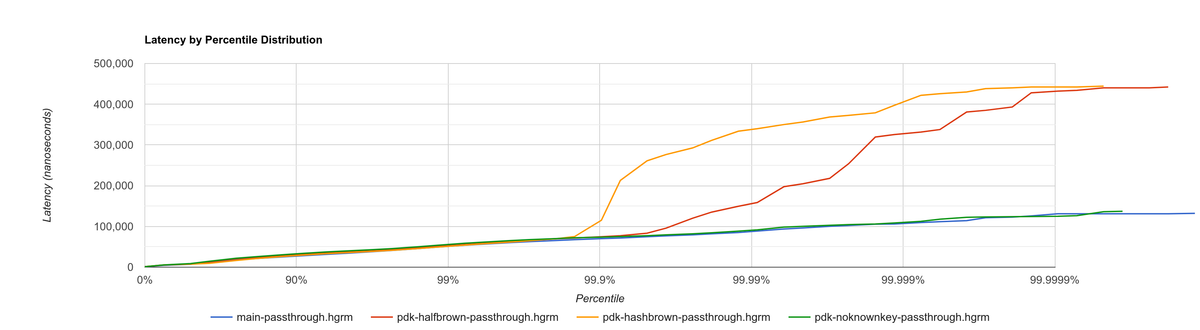
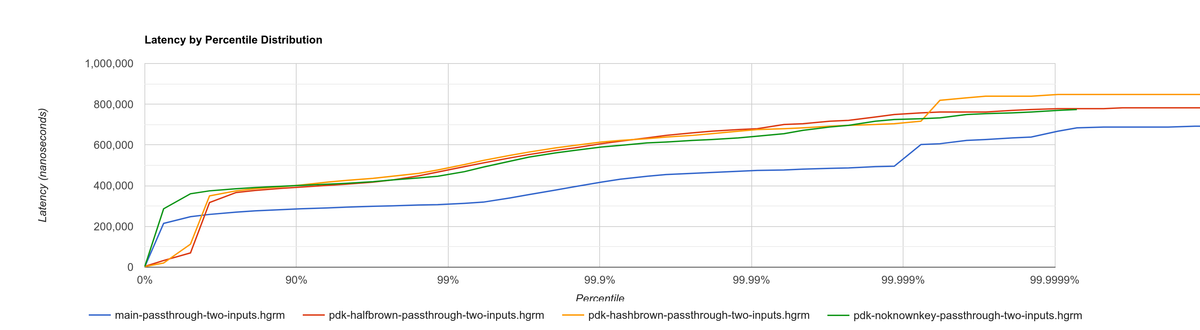
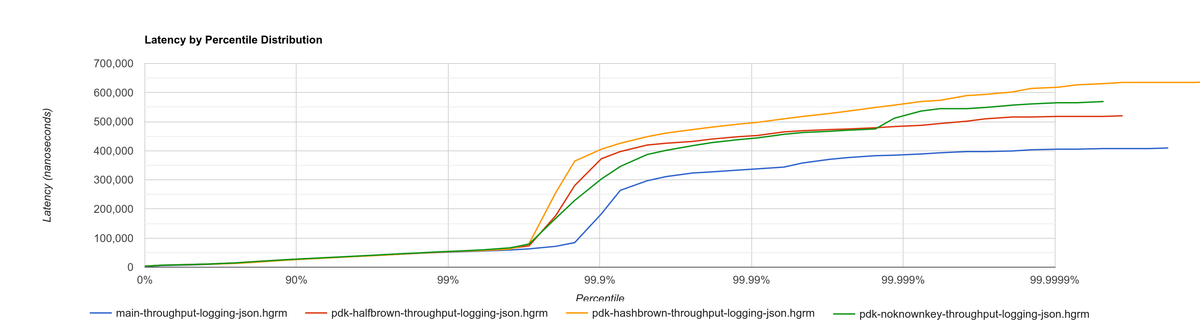
This time I did it right since the beginning and tried multiple benchmarks. The results are much more varied now, and the efficiency can be analyzed from multiple points of view:
Histogram for passthrough, which simply redirects input events from a single source to the output:
Histogram for passthrough-two-inputs, which redirects input events from two different sources to the output:
Histogram for throughput-logging-json, which also implements some event processing logic over JSON data:
Histogram for throughput-logging-msgpack, which also implements some event processing logic over MessagePack data:
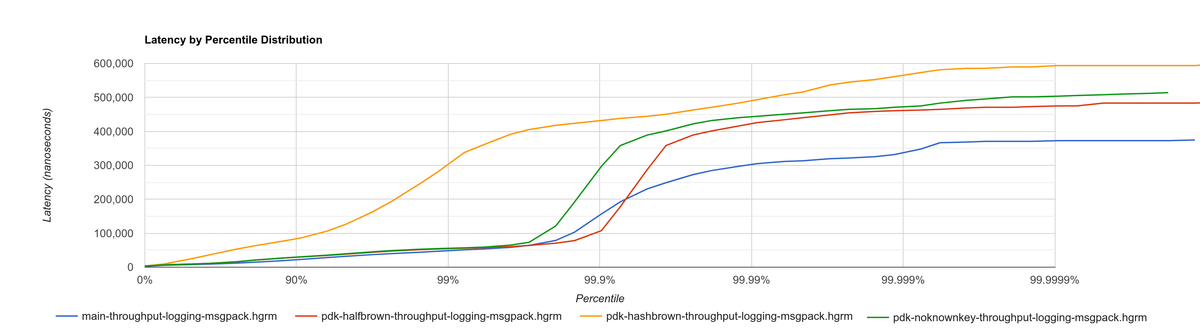
Relative performance for number of events processed per second (higher is better):
| Benchmark | No plugin system (%) | Halfbrown, No JSON Known Key (%) | Halfbrown (%) | Hashbrown (%) |
|---|---|---|---|---|
| Passthrough | 100 | 77.39 | 76.33 | 70.86 |
| Passthrough Two Inputs | 100 | 70.34 | 69.78 | 68.76 |
| Throughput Logging JSON | 100 | 65.57 | 64.48 | 69.21 |
| Throughput Logging MsgPack | 100 | 66.66 | 65.52 | 70.69 |
| Average | 100 | 69.99 | 69.02 | 69.88 |
They seem to point out that, with the plugin system, hashbrown (the standard hash table) might actually be better than halfbrown. The JSON optimization I mentioned could possibly be worth removing now. But it’s really hard to make a decision just out of this set of benchmarks because of the complexity of the change.
This time, the experiment is only done for investigation. These results must only be taken as an indicator of something worth investigating more in depth; it would be premature to make assumptions so early and remove halfbrown. We would need to also analyze the impact of using hashbrown without the plugin system, and understand why this happens. For example, taking a look at the flamegraphs could help in figuring out the underlying reasoning.
abi_stable
We can also take a look at the recurring occurrence of an experiment that isn’t worth pursuing. abi_stable imposes all kinds of overheads, apart from the type validation step before loading a plugin. I wanted to learn more about the Drop implementations, which require accessing to a vtable, and in cases like RBox, dealing with additional logic to ensure everything is safe[2].
After zooming into specific sections, we can see this overhead by ourselves in the call stack. Here’s the flamegraph with abi_stable’s complex destructors, shown in pink and zoomed in:
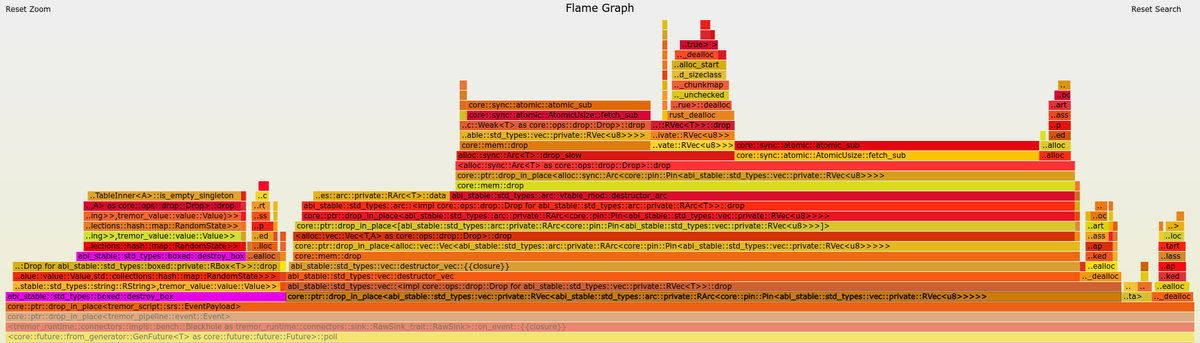
However, I overestimated the importance of this problem. Taking a look at the big picture, it’s obvious that optimizing RBox’s implementation of Drop isn’t worth it yet. Here’s the flamegraph with abi_stable’s complex destructors, shown in pink and without zooming in:
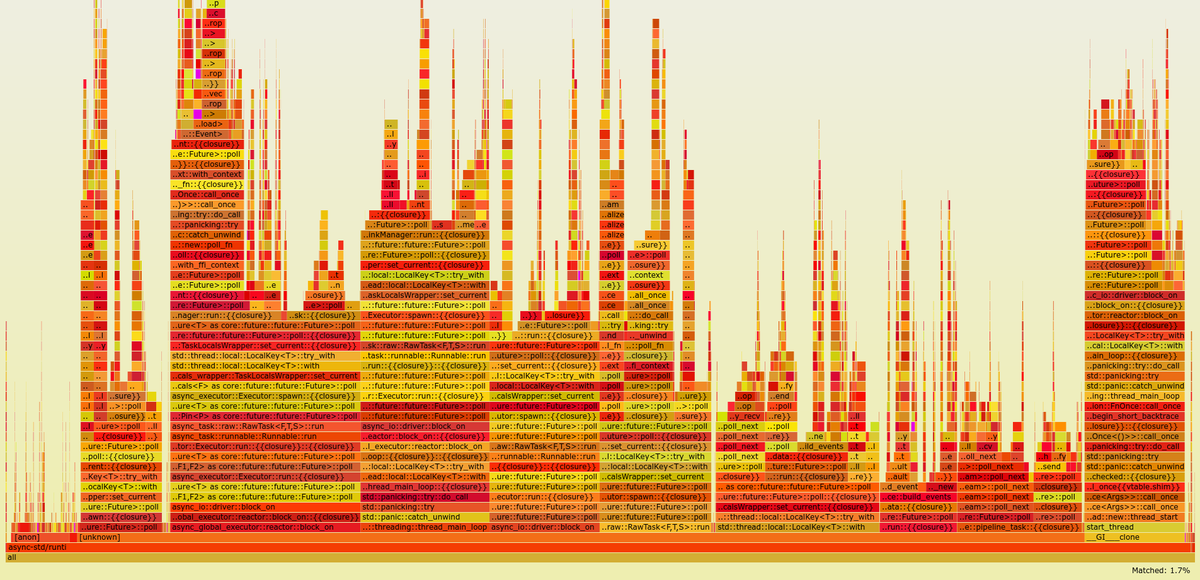
I’m definitely taking note of this idea in order to investigate about it in the future for further performance squeezing. But I currently have lots of other more impactful experiments in mind with a higher priority.
Unimplemented ideas
It’s already been a year since I started working with Tremor. I extended the mentorship from three months to twelve so that I could use it as my bachelor’s thesis (see “My Final Year Project”).
But now that I have finally graduated and need to find a full-time job, I won’t be able to continue experimenting with the plugin system. My hope is that with the information in this series, the Tremor team can keep improving the plugin system so that it’s ready for deployment. The same applies to anyone reading this; hopefully you’ll have enough pointers to continue on your own after this.
Here are some ideas worth considering that I haven’t been able to carry out:
More detailed benchmarking
perf can track much more information than just the call stack. For example, perf stat provides statistics like cache or branch misses[3]. Other profiling tools like Valgrind, AMD μProf, or Heaptrack may provide more specialized insights[4]. The whole The Rust Performance Book is a great read for more resources and ideas.
Investigate wrapper overhead
The communication between runtime and plugins is handled through the C ABI at a lower level. To improve the ergonomics internally, the interface is accompanied by a set of wrappers, which convert the types to the standard library.
Instead of returning a Result, the following raw function uses the FFI-safe alternative RResult, which doesn’t even work with ? for error handling. This example is quite specific to abi_stable, but what’s important is that we just wrap the base function connect and transform it to an easier to use one.
Low-level interface to communicate between binaries:
#[abi_stable::sabi_trait]
pub trait RawConnector: Send {
fn connect<'a>(
&'a mut self,
ctx: &'a ConnectorContext,
attempt: &'a Attempt,
) -> BorrowingFfiFuture<'a, RResult<bool>>;
}
/// Alias for the FFI-safe dynamic connector type
pub type BoxedRawConnector = RawConnector_TO<'static, RBox<()>>;High-level wrapper for what essentially is a Box<dyn RawConnector>:
pub(crate) struct Connector(BoxedRawConnector);
impl Connector {
#[inline]
pub async fn connect(&mut self, ctx: &ConnectorContext, attempt: &Attempt) -> Result<bool> {
self.0
.connect(ctx, attempt)
.await
.map_err(Into::into) // RBoxError -> Error::PluginError
.into() // RResult -> Result
}
}Here we just convert the return types, but we can do the same for the parameters or whatever boilerplate is needed for that function. Note that this wrapper only needs to be available in the runtime crate; the plugin is only meant to implement RawConnector and doesn’t need access to Connector.
The problem is that, even though wrappers reduce the much dreaded boilerplate, they can also affect performance-critical parts considerably. connect is only called at the beginning of the program, but on_event is invoked for every single event in the source, making it our hot loop. Any small operation, like a type conversion, will have a much greater impact in there. This experiment consists on iteratively removing wrappers and looking for performance improvements.
Investigate async runtime conflicts
As far as I understand, the runtime and the plugins don’t share the same async runtime state. Every binary has its own thread pool and works independently. It would be best to share everything between runtime and plugins, though it sounds incredibly complicated, and it would most likely require contributions to the async runtimes themselves.
I also wonder what happens when the runtime and the plugin use different async runtimes, even if they are independent in the binaries. Tremor’s core is implemented with async_std, but an external plugin could freely use tokio, for example. I’ve heard that this could break in many ways, since async runtimes heavily rely on global state.
Testing different async runtimes should be easy, so it should at least be done before reaching production just to document the behavior. What I’m not so sure about is how to avoid the conflict, in case it was problematic. The fix would probably be hacky, as this is a somewhat obscure problem.
Benchmark async_ffi
Checking how much of a performance impact async_ffi causes sounds like a good idea. It’s actually a quite simple library; all it really does is implement opaque wrappers for the async-related types. But it’s used so often (once per call), that it may end up being noticeable.
I’m sure that if async_ffi ended up being an issue, it could be optimized internally in various ways. Furthermore, we currently use async very liberally. Only using it when strictly necessary could also help reduce the overhead.
Improve error reporting
For simplicity, errors in our interface are reported via abi_stable’s SendRBoxError, which is basically a Box<dyn Error + Send>. It’s really the only way to do it, because a plugin could have any kind of error, and we can’t know them at compile-time.
Using Box<dyn Error> instead of a concrete type makes it really hard to identify and handle specific errors. We could implement our own Error subtrait that provides more plugin-related information. An easier option is to define a more organized data structure with common kinds of errors. Here’s an example of a more organized error type, even if it still uses Box<dyn Error>:
pub struct PluginError {
err: SendRBoxError,
kind: PluginErrorKind
}
pub enum PluginErrorKind {
Internal, // Implementation-defined errors we can't handle
ConnectionFailed, // Edge cases in `connect`
// ...
}Reduce error handling boilerplate
In the plugin system we have to use an FFI-safe type like RResult instead of Result. Since the Try trait isn’t stable[5], we can’t use the ? operator yet. abi_stable exports the rtry macro as a substitute for ?, but in my experience it introduces noise in the code, making it uglier and harder to maintain.
Depending on how much Try is going to take to stabilize, creating a procedural macro might be worth our time. It would just replace ? with rtry or whatever is configred, which should be somewhat simple to implement. I’m surprised I couldn’t find an existing crate for that. Readability would improve in longer functions with lots of error handling:
+#[try_with(rtry)]
fn fallible() -> RResult<()> {
- if rtry!(fallible_op_1()) && rtry!(fallible_op_2()) {
- rtry!(fallible_op_3());
+ if fallible_op_1()? && fallible_op_2()? {
+ fallible_op_3()?;
}
ROk(())
}
Admittedly, the example above is an oversimplification. In reality, a single function may mix both Result and RResult, or require type conversions. The macro would probably end up being a bit more complex, but it might be worth considering regardless.
Reduce async boilerplate
async_ffi would really benefit from a procedural macro as well. It always requires using async move { /* ... */ }.into_ffi(), which is quite a bit of boilerplate and increases the indentation level by one.
Without the procedural macro:
use async_ffi::{FfiFuture, FutureExt};
#[no_mangle]
pub extern "C" fn work(arg: u32) -> FfiFuture<u32> {
async move {
let ret = do_some_io(arg).await;
do_some_sleep(42).await;
ret
}
.into_ffi()
}With the procedural macro, especially noticeable in more complex functions:
use async_ffi::async_ffi;
#[no_mangle]
#[async_ffi]
pub async extern "C" fn work(arg: u32) -> u32 {
let ret = do_some_io(arg).await;
do_some_sleep(42).await;
ret
}I already opened an issue about this with more details for whoever wants to give it a try:
Improve cross-platform support
As I mentioned in earlier articles, our plugin system will only work on Windows, macOS, and Linux[6]. It will still compile on other platforms, but possibly with data races in the dynamic linking internals.
Specifically, libloading, which is used by abi_stable, states that its error handling isn’t fully thread-safe on some platforms[7], such as dlerror on FreeBSD. Its only consequence should be garbage error messages, but I still wouldn’t risk it. There are two ways to approach this:
-
Quick fix: add a compile-time error for any platform that isn’t explicitly supported. Before adding support for a new platform, we will have to manually ensure that its error handling for dynamic loading is thread-safe.
// Ideally, there should be a comment here with references that state the // thread-safety of the supported platforms. #[cfg(not(any(unix, windows, target_os = "macos")))] compile_error!( "This platform isn't currently supported. Please open a ticket on GitHub." ); -
Proper fix: fix the data races upstream with an internal mutex. This is what the alternative
dlopendoes, though in their case they always have the mutex, which is unnecessary in some platforms[8].
Performance impact of panic handling
abi_stable has to track all panic occurrences so that they don’t propagate through the FFI boundary. Otherwise, as discussed in other articles[9][10], we would be invoking undefined behaviour. async_ffi also has special handling for panics, which overcomplicates the crate a bit.
There are two interesting experiments to try:
-
Comparing the performance of
panic = "abort" andpanic = “unwind”. Technically, aborting should optimize away most of the extra code[11], but it should only be used for research, as it would make debugging in production incredibly hard. -
Preparing
abi_stableandasync_ffifor the stabilization ofextern "C-unwind", thanks to which all the additional panic handling could be removed. Unlike aborting, we would still be able to debug errors just fine.For now, it’s only available on nightly without a certain release date, but it will surely be useful in the future, and we could measure how much panic handling costs. Testing new features like that also speeds up their release, since we could share feedback with the project group.
Use -Z randomize-layout to find FFI bugs
The unstable compiler flag -Z randomize-layout randomizes the layout of #[repr(Rust)] types. The Rust ABI is unstable: it explicitly doesn’t specify much about the type layouts, and we must not rely on them. However, in practice they’re usually consistent, at least within the same compiler version[12], so these errors can be hard to catch without a tool like this.
We use #[repr(C)] for the plugin system, so this flag shouldn’t cause any issues… unless we’re mistakenly interacting with the Rust ABI. In that case, the program would crash in random and unexpected ways, pointing out that there’s something wrong. It certainly won’t be a pleasant debugging experience, but it’s better than having it happen in production.
This may even catch other bugs unrelated to the project. Tremor implements self-referential types and other optimizations, and it’s possible that some of them incorrectly rely on the Rust ABI.
Tremor’s Continuous Integration tests could be run with -Z randomize-layout to ensure that no opaque types export Rust types, even if abi_stable prevents most cases within the plugin system.
Try raw dynamic loading
What I didn’t know at the beginning of this journey is that the hardest part would be making everything #[repr(C)]. Using abi_stable is certainly very useful for types like RVec and to create custom types, but at times I find the library too much.
A few developers, including myself, think that it would be best to have separate libraries for all the utilities abi_stable provides, rather than bundling everything in there. If they became modularized, making it the “community standard” would be easier, and we could have compatible alternatives for different preferences.
It also boils down to just having more support from the community. abi_stable is an incredibly complex library, and I want to give props to the legend rodrimati1992 for creating and maintaining it. But such complexity makes it a scary crate to contribute to, which I know first-hand. Turning it into smaller crates would really help decentralize the work, in my opinion.
Anyway, the point of this experiment is that abi_stable isn’t a hard requirement for the plugin system. Using it definitely makes its implementation easier, but also introduces many overheads. Its main selling points are usability, safety, and backward compatibility, though with enough effort and care, we could write the plugin system by ourselves just with libloading.
It would be super useful to measure how much performance could be squeezed out by removing abi_stable. This doesn’t need to be done over the full plugin system; we could benchmark smaller prototypes, like the ones I host at marioortizmanero/pdk-experiments.
Simplify the interface further
I’m not fully satisfied with what the final interface for the plugin system looks like either. For the first version, all I did was change as little as possible so that we could have a working prototype. But there are many parts that could be simplified with dedicated refactors.
Everything could be reorganized and cleaned up a bit, especially the plugin initialization and the repetitive opaque types. We should continue to minimize the use of complex communication patterns like channels. These improvements can be worked on iteratively, because you will only come up with new ideas over time.
For the long-term future
Our short-term goals focus on either usability or performance. However, there are more ways in which our plugin system could keep evolving afterwards:
- Supporting more components in the plugin system. We could keep splitting up the executables into even smaller pieces, continuing to improve the overall flexibility and compilation times.
- Refining the user experience by making the plugin loading smarter and easier to use. In the far future, we could even have a centralized repository with all the plugins, so that it’s as easy as possible to download and add them. You can think of crates.io or hub.docker.com.
- Improving the developer experience is also essential. Anyone should be able to implement their own plugin, but ours is currently too tied to the internals of Tremor. We could create project templates, properly document everything, write examples, etc.
- Security is something we sacrificed when we chose dynamic loading as our base technology. We don’t have a sandbox, which would be essential if a plugin repository were to exist.
- Restarting or unloading plugins at runtime. Unloading is almost impossible, given that
abi_stableexplicitly doesn’t support it[13]. But restarting could work by simply stopping and leaking an existing plugin, and then loading it again with the same config. It would improve error resilience considerably, as we would be able to restart plugins upon failure (cautiously, or we could run out of memory after leaking too much).
Conclusion
That was all! In summary, our new FFI interface initially slowed down the program by around 36%. In a few iterations, we’ve reduced that number to around 30%, and there are still many ideas left to try.
The complexity of the whole project has turned out to be much greater than we predicted at the beginning. I still remember when we were unaware of the ABI instability and thought we could get away with an interface in pure Rust. Thus, I haven’t been able to attain some goals specified initially, and there’s still a bit of work left before reaching production, mainly related to performance.
However, I’m sure my implementation will serve as a great base for what the plugin system may evolve into in the future! And hopefully, this series and my contributions (see “Open Source Contributions”) will make plugin systems more accessible, even outside Tremor.
Doing all of this in an open source environment has been enormously rewarding. Even if you’re working for a company with propietary software, please try to contribute upstream instead of forking or patching. Try to pay it back to those who save you from so much work, and submit a PR or an issue.
This project has been possible thanks to Darach, Heinz, and Matthias, my mentors in the Tremor team ❤️. Thanks to Wayfair as well for supporting open source, and for funding this project. And one final thanks to the Rust community for motivating me to continue with the series, and for providing such splendid libraries and tools.
Please leave a comment below for any questions or suggestions you may have. Also let me know of new advances on any of the ideas above, so that I can add a link for future readers. I would love to see your plugin system creations and results :)
Appendix A: Open Source Contributions
One of my favorite parts of the project has been contributing so much to all kinds of open source dependencies, so I’ve maintained a list of its occurrences. Some are more important than others, but it’s still a decent metric for my results. This skips the issues or pull requests that:
- Contributed nothing (e.g., asking questions or discarded ideas).
- Were repetitive (e.g., I made a few identical PRs in Tremor when I was fixing problems with Git).
External Contributions
These include repositories not directly related to Tremor:
- Subtyping and Variance - Trait variance not covered rust-lang/nomicon#338
-
dlerroris thread-safe on some platforms szymonwieloch/rust-dlopen#42 - Add deprecation notice to the crate
wasmer-runtimewasmerio/wasmer#2539 - Support for
abi_stableoxalica/async-ffi#10 - Cbindgen support oxalica/async-ffi#11
- Procedural macro for boilerplate oxalica/async-ffi#12
- Generating C bindings rodrimati1992/abi_stable_crates#52
- Stable ABI for floating point numbers rodrimati1992/abi_stable_crates#60
- Fix ‘carte’ typo rodrimati1992/abi_stable_crates#55
- Fix some more typos rodrimati1992/abi_stable_crates#57
- Add support for .keys() and .values() in RHashMap rodrimati1992/abi_stable_crates#58
- Implement
Indexfor slices and vectors rodrimati1992/abi_stable_crates#59 - Support for
f32andf64rodrimati1992/abi_stable_crates#61 - Implement
ROption::as_derefrodrimati1992/abi_stable_crates#68 - Implement
RVec::appendrodrimati1992/abi_stable_crates#70 - Fix
R*lifetimes rodrimati1992/abi_stable_crates#76 - Fix inconsistencies with
RVecin respect toVecrodrimati1992/abi_stable_crates#77 - Implement
ROption::{ok_or,ok_or_else}rodrimati1992/abi_stable_crates#82 -
RHashMap::raw_entry[_mut]support rodrimati1992/abi_stable_crates#83 - Fix hasher rodrimati1992/abi_stable_crates#85
- Only implement
Defaultonce rodrimati1992/abi_stable_crates#88 - Support for
abi_stablesimd-lite/simd-json-derive#9 - No docs for v0.3.0 simd-lite/simd-json-derive#10
- Add support for StableAbi simd-lite/value-trait#14
- User friendliness for the win! (close #15) simd-lite/value-trait#16
- Update abi_stable after upstreamed changes simd-lite/value-trait#18
- Small typo nagisa/rust_libloading#94
- Fix typo szymonwieloch/rust-dlopen#40
- Implement
remove_entryLicenser/halfbrown#13 - Implement
CloneandDebugforIterLicenser/halfbrown#14 - Relax constraints Licenser/halfbrown#16
- Same
Defaultconstraints Licenser/halfbrown#17 - Fix
Clonerequirements forIterLicenser/halfbrown#18
Internal Contributions
Here are the issues and pull requests created within Tremor’s repositories, including those for the plugin system and other unrelated improvements:
- PDK support tremor-rs/tremor-runtime#1434
- PDK with a single value marioortizmanero/tremor-runtime#11
- Fix
makefile benchtremor-rs/tremor-runtime#1447 - Adding
abi_stablesupport fortremor-scriptmarioortizmanero/tremor-runtime#2 (second attempt) - Adding
abi_stablesupport fortremor-runtimemarioortizmanero/tremor-runtime#1 (second attempt) - Adding
abi_stablesupport fortremor-valuetremor-rs/tremor-runtime#1303 (second attempt) - Plugin Development Kit: Connectors tremor-rs/tremor-runtime#1287 (first attempt)
-
denystatemements inlib.rsshould be enforced in the CI rather than in the code tremor-rs/tremor-runtime#1353 -
KnownKeyrelies on a deterministic hash builder tremor-rs/tremor-runtime#1812 - Fix wrong links in getting started tremor-rs/tremor-www#72
- Redirect
docs.tremor.rstowww.tremor.rs/docstremor-rs/tremor-www#73 - Links pinned to 0.12 don’t work tremor-rs/tremor-www#186
- Small fix in code snippet tremor-rs/tremor-www#187
- No margins in benchmark page tremor-rs/tremor-www#195
- Fix typos in benchmarks page tremor-rs/tremor-www#219
Appendix B: Other Achievements
Breaking the Compiler
I also managed to break the Rust compiler while working on this plugin system. It may not be as rare as one would think, but for some reason I felt oddly proud to achieve it, so I’ll share it here :)
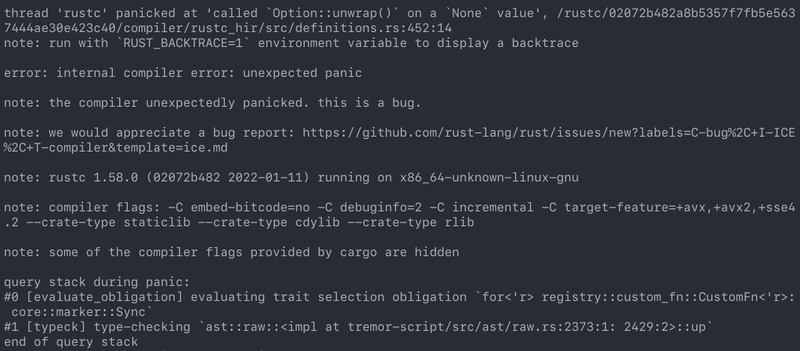
It’s seemingly related to incremental compilation, and someone had already reported it before. It should be fixed in a future version, and I haven’t come across it again.
LFX Mentorship Showcase
I already shared this in a previous article, but for completeness I’ll repeat it here. This online event made it possible to showcase my work back in January with a quick 15-minute presentation. I couldn’t get into many technical details, but I’m sure it will be useful to anyone considering participating in a LFX Mentorship or in Google Summer of Code.
My Final Year Project
I have finally recently submitted this as my bachelor’s Final Year Project. This document takes a more academic approach, and I rigorously reorganized everything so that even developers unfamiliar with Rust can understand it. The abstract is in English, but unfortunately, the rest is in Spanish due to absurd university rules.
KubeCon + CloudNativeCon 2022
Thanks to the Tremor team, I was also able to presentially attend KubeCon + CloudNativeCon 2022 in Valencia, Spain! It was my first conference and I was very pleasantly surprised by how nice everyone was. I had tons of fun and met smart folk with all kinds of backgrounds. If you’re on the fence about attending something similar, I strongly recommend you to go for it!
Paella! From my LinkedIn profile:

Footnotes
@Amanieu’s comment — Tracking issue for HashMap::raw_entry ↩︎
Thread safety — Plugins in Rust: Reducing the Pain with Dependencies, NullDeref ↩︎
dlerroris thread-safe on some platforms szymonwieloch/rust-dlopen#42 ↩︎Panicking — Plugins in Rust: Reducing the Pain with Dependencies, NullDeref ↩︎
Panicking — Plugins in Rust: Diving into Dynamic Loading, NullDeref ↩︎
Unwinding the Stack or Aborting in Response to a Panic — The Rust Programming Language ↩︎
ABI unstability, it’s much worse than it seems — Plugins in Rust: Getting Started, NullDeref ↩︎
Non-features (extremely unlikely to be added) — GitHub rodrimati1992/abi_stable_crates ↩︎