Table of Contents
Welcome to one of the last articles of this series! Previously, we covered how to use external dependencies to lessen the work necessary to implement our plugin system. Now that we know how to actually get started, we’ll implement it once and for all.
I will personally use the crate abi_stable, but the concepts should be roughly the same for any dynamic loading method. Similarly, some of my advice is related to modifying an already existing project of large size. If you’re starting from scratch with a plugin system in mind, it should be the same, just easier in some aspects.
Some prototyping advice
Before anything else, I’d like to give out some suggestions regarding refactoring with Rust, based on my experience. You’ll be introducing a lot of changes, so it would be wise to do some brief planning beforehand — otherwise it’ll take forever with a complex enough codebase. Maybe this will all be obvious to you, or you may prefer taking a different approach. But it certainly worked for me, so it’s worth a shot. I’m personally very satisfied with how much I’ve learned about the process.
The “just make it work” approach
What I personally struggled the most to get drilled into my head is not getting lost in the details. First of all, we just want it to work. I’ll repeat. First of all, we just want it to work. As long as the plugin system runs, the following are completely fine:
- Ugly code (non-idiomatic, repetitive, somewhat messy, etc)
- Non-performant code
- Poor documentation
- No tests
- No clippy
Or, more specific examples:
- If stuck with lifetimes, just slap a
.clone()in there and call it a day. - A good ol’
.unwrap()will make your life easier in case of doubt. - You can resort to “dirty” or unnecessary type conversions if necessary.
- Just pulling in a new dependency instead of implementing something more tailored to your use-case from scratch will save you a lot of time.
- If something that’s not really important is taking you too much time, you can always resort to a
// TODOor// FIXME.
I will say that not working on tests until the plugin system is running is definitely arguable for those who prefer to follow a test-driven development. However, I personally didn’t feel the need to write any tests in this case; thanks to Rust’s strong type system, it was mostly a compiler-driven development. My progress basically consisted on making some changes and then trying to make the compiler happy about them, repeatedly. I only moved to the testing step once I was happy enough with the results, and everything seemed to work when running it manually.
Furthermore, premature optimization is the source of all evil. You’re not at a point where that’s important yet. Once you’re done, you can actually spend some time profiling and benchmarking in order to know which optimizations are worth your time. Don’t get me wrong — you can certainly worry about choosing an approach that’s appropriate in terms of performance, which is why I discarded WebAssembly or IPC at the beginning. But definitely give up on trying to avoid a clone that might not actually affect your program speed after all.
My point is that every test, clean-up or optimization you try to make at this stage will very likely end up being wasted effort. You’ll reach a blocker at some point later on, and have to rethink and rewrite lots of stuff. When everything compiles, seemingly runs fine, and you consider it a decent approach, you can actually start working on these points. Just keep note of what can be improved so that you don’t forget.
Note that it is okay to “waste” effort on wrong approaches, because you aren’t really “wasting” it; they’re a necessary step to arrive to the final solution. But it’s painful to delete code you’ve spent time thinking about, so we should at least try to minimize it.
Specific to Rust
Disable the annoying warnings
The first thing I did was remove some warnings the compiler will print when you’re prototyping. By default, a Rust program still compiles with warnings, but in my experience, they’re always in the way when trying to deal with actual errors. For example, I don’t care that an import is unused at all. I’ll fix it once I’m done, but please let me keep trying to “make this work”!
// TODO: disable and cleanup with `cargo fix` automatically once done
#![allow(unused)]
#![allow(dead_code)]Note that I’m not using #![allow(warnings)], because most warnings will actually be really helpful when refactoring to avoid early bugs. We just want to get rid of the annoying ones, such as unused functions or imports, or dead code that we haven’t cleaned up yet, which are usually harmless.
One month later, I was able to finally compile tremor-runtime with the initial prototype. This screenshot made my day, as simple as it may seem:

Afterwards, I removed these allow statements, ran cargo fix && cargo fmt, and cleaned up a bit. cargo fix is built-in, and will automatically take care of the trivial warnings, such as unused imports, saving lots of time doing cumbersome work.
Don’t touch previous use statements
As my Pull Request got bigger and bigger, I started running into problems with Git. The parent branch was also undergoing changes from a team of three people, so it was updated quite often. All of this resulted into frequent conflicts, and having to painfully resolve them many times until I got the hang of it.
Say, you have a number of use statements at the top of your file. After adding some changes related to the plugin system, you now need to import PdkValue as well. You’d usually do:
-use tremor_value::{Value, ValueTrait};
+use tremor_value::{Value, ValueTrait, PdkValue};
The problem is that if the parent branch later adds or removes one of the items in that use statement, you may encounter a conflict. Git isn’t smart enough to handle Rust import statements (although that’d be pretty cool). Multiply this by 100 statements, and you might eventually go crazy. You can keep your sanity by adding the new item in a separate block of uses instead:
-use tremor_value::{Value, ValueTrait};
+
+use tremor_value::PdkValue;
Same thing may happen if tremor_value wasn’t imported and you have to add a new line to the already existing use block:
use more_stuff::{X, Y, Z};
+use tremor_value::PdkValue;
use other_stuff::{A, B, C};
In my experience, Git also trips up with this sometimes. You can follow the same advice:
use more_stuff::{X, Y, Z};
use other_stuff::{A, B, C};
+
+use tremor_value::PdkValue;
In summary, you can just create a new block after all the previous uses and add your stuff in there. You can clean it up at the end or in a different pull request.
This is harder to do if you’re removing use statements. But if you also followed the previous section about ignoring annoying warnings, it won’t be a problem in the first place. You can just leave the unused imports and clean up when you’re done with the PR.
Defining the plugin interface
The first step that we can do is define the interface of the plugin system, i.e., what a plugin binary must implement in order to be loadable by the runtime. If you’re doing this over an already existing codebase, you’ll probably get tons of errors. We’ll ignore them for now; this is only our first sketch, and you’ll end up changing it a thousand times anyway. Some types in the interface may not exist yet, or they may not be meant to be used for FFI. But it’ll serve us as an initial list of things to work on.
In my case, it first looked as follows. The specifics about how this works with abi_stable are explained in the previous post.
/// This type represents a connector plugin that has been loaded with
/// `abi_stable`. It serves as a builder, making it possible to construct a
/// trait object of `RawConnector`.
#[repr(C)]
#[derive(StableAbi)]
#[sabi(kind(Prefix))]
pub struct ConnectorMod {
/// the type of the connector
pub connector_type: extern "C" fn() -> ConnectorType,
/// create a connector from the given `id` and `config`
///
/// # Errors
/// * If the config is invalid for the connector
#[sabi(last_prefix_field)]
pub from_config: extern "C" fn(
id: RString,
config: ROption<Value>,
) -> FfiFuture<RResult<BoxedRawConnector>>,
}
/// Marking `ConnectorMod` as the main module in this plugin. Note that
/// `ConnectorMod_Ref` is just a pointer to the prefix of `ConnectorMod`.
impl RootModule for ConnectorMod_Ref {
/// The name of the dynamic library
const BASE_NAME: &'static str = "connector";
/// The name of the library for logging and similars
const NAME: &'static str = "connector";
/// The version of this plugin's crate
const VERSION_STRINGS: VersionStrings = package_version_strings!();
/// Implements the `RootModule::root_module_statics` function, which is the
/// only required method for the `RootModule` trait.
declare_root_module_statics! {ConnectorMod_Ref}
}My task was to turn the Connector trait into a plugin. All the Connector implementors were meant to be constructed with ConnectorBuilder, and from that moment on Tremor was able to use them generically with dyn Connector. Thus, I thought the best idea would be to turn ConnectorBuilder into my RootModule under the name ConnectorMod. Once the plugin was loaded, it would be possible to construct the connector with the from_config function. I used abi_stable::sabi_trait’s macro functionality, making dyn usage possible within FFI.
For reference, when I first wrote ConnectorMod, Value wasn’t even #[repr(C)]. I had also added the #[sabi_trait] attribute to the RawConnector trait declaration, but the types used there weren’t #[repr(C)] either. So I had tons of errors everywhere, but that was OK. I would be working on them step by step until it compiled again.
If you’re using libloading directly then you would be implementing
the interface via a struct with function pointers instead, and you’d need to
store metadata about the plugin with constants. But in the end, it boils down to
the same thing; just with different amounts of boilerplate.
Recursively making everything #[repr(C)]
Now, this is the actually complicated part. The previous step may have seemed simple, but you might find yourself falling into madness as you realize that you need to make all the types in your interface #[repr(C)], and also all the fields each of these types hold, and so on…
It’s very likely that you’ll eventually find types without an FFI alternative in abi_stable. These will most likely be external types, but things like async are a bit complicated to deal with as well. In the case of Tremor, the most problematic part was the Value type. It’s used to represent a JSON-like payload; roughly defined as follows:
pub enum Value {
/// Static values (integers, booleans, etc)
Static(StaticNode),
/// String type
String(String),
/// Array type
Array(Vec<Value>),
/// Object type
Object(Box<HashMap<String, Value>>),
/// A binary type
Bytes(Vec<u8>),
}In order to be able to use Value in the plugin system, it can be converted to:
#[repr(C)]
#[derive(StableAbi)] // Only necessary for abi_stable
pub enum Value {
/// Static values (integers, booleans, etc)
Static(StaticNode),
/// String type
String(RString),
/// Array type
Array(RVec<Value>),
/// Object type
Object(RBox<RHashMap<RString, Value>>),
/// A binary type
Bytes(RVec<u8>),
}The first problem arises in the Static variant: StaticNode is a #[repr(Rust)] external type. It’s from our value_trait dependency, and it may hold different basic types: numbers, booleans, or just nothing.
pub enum StaticNode {
I64(i64),
U64(u64),
F64(f64),
Bool(bool),
Null,
}This could be fixed by simply applying the very same procedure again (hence recursively until everything is #[repr(C)]). Here it will finally work because there aren’t any other #[repr(Rust)] types in StaticNode:
#[cfg_attr(feature = "abi_stable", repr(C))]
#[cfg_attr(feature = "abi_stable", derive(abi_stable::StableAbi))]
pub enum StaticNode {
I64(i64),
U64(u64),
F64(f64),
Bool(bool),
Null,
}Since it’s an external library, we’ll have to make a Pull Request and hope that the author is okay with the changes. abi_stable should be optional so that this change is applied only to those that actually need #[repr(C)] in the library. You could also go a step further and differentiate between enabling #[repr(C)] and deriving StableAbi for those that don’t need the latter.
Add support for StableAbi simd-lite/value-trait#14
Overcoming problems with #[repr(C)]
Awesome. We got Value working now for FFI. Right? No? Oh. It seems like the compiler strongly disagrees. By changing the variants of Value, a great amount of the code that used it will now fail to compile in multiple ways:
// Won't work because Value::Array holds an RVec now
let value = Value::Array(Vec::new());That’s the easiest one: we just need to change Vec to RVec and it should be fine. The types in abi_stable are meant to be a drop-in replacement for the ones in std:
let value = Value::Array(RVec::new());It gets a bit more complicated when the old types are exposed in methods, because you have to decide whether to expand the FFI boundary from the internals of Value to the users of Value. For instance, the Value::Object variant holds a RHashMap now, but the method Value::as_object used to return a reference to a HashMap. You’ll get another error in there, which raises a decision that must be made: returning RHashMap or adding an internal conversion to HashMap.
impl Value {
// Original code
fn as_object(&self) -> Option<&HashMap<String, Value>> {
match self {
// Problem: `m` is a `RHashMap` now, but the function returns a
// `HashMap`.
//
// Solution 1: change the return type to `RHashMap`
// Solution 2: convert `m` to a `HashMap` with `m.into()`
Self::Object(m) => Some(m),
_ => None,
}
}
}-
If the return type is changed to
RHashMap, almost every caller toas_objectin the program will now fail to compile because they expect aHashMap. You’ll have to clean it up one by one and figure out howRHashMapcan be used in that case instead.This can be messy because in order to avoid conversions, your plugin system will infect the entire codebase. You may quickly find yourself propagating the usage of
RHashMapeverywhere, even when the system isn’t that important. For example,Valuealso appeared in Trickle’s implementation, the scripting language used to configure Tremor’s pipelines. Having to useRHashMapin there was a bit confusing, and I was modifying lots of files unrelated to the plugin system. -
If you perform an internal conversion to
HashMapinas_objectwe’ll avoid all of these errors, at the cost of adding a small overhead. It’s by far the easiest choice, but ifValue::as_objectis frequently used in, e.g., your hot loop, you may notice a considerable performance degradation.
I already investigated in the past, and the good news is that converting between types in std and abi_stable is $O(1)$. Most of the times it’s equivalent to a pointer cast or a match. So here’s when the “just make it work” approach is useful: we’ll just keep the FFI boundary minimal and add conversions as early as possible. After we’re done, we’ll see if there are any performance issues, and then work on them.
Reaching #[repr(C)] blockers
That was my first attempt at making Value FFI-compatible, and unfortunately, it didn’t end there. Converting from std to abi_stable is a relatively painless experience; their usage intends to be the same. The only issue I found in that regard is that some methods from std weren’t available in abi_stable yet because it’s not updated as regularly. Usually, you can just copy-paste the implementation from std into abi_stable's and create a new Pull Request, which is what I did a few times:
However, this stops being as “easy” when you have to convert from an external library to abi_stable. I lied at the beginning of the article: the declaration of Value was an oversimplification. For performance reasons, Tremor actually uses halfbrown's implementation of a hash map instead of std::collections::HashMap.
NOTE: halfbrown is based on hashbrown, which was, in fact, merged into the standard library at some point[1]. Although with this plugin system we’re suffering the consequences of not having a stable ABI, seeing that it enables things like that makes me less bitter.
halfbrown has some additional functionality over std’s implementation. Some of it is actually available on Nightly, but for that reason it’s not meant to be in the stable RHashMap either. This extra functionality is used in Tremor for example with raw_entry. There is an optimization for JSON handling that consists on memoizing the hash of a known item in a map in order to access its value directly with it[2]. After switching to RHashMap, this becomes an impossible task.
Even if I managed to fix the hash map mess, the same story repeats itself for Cow. Tremor uses beef's Cow instead of std::borrow::Cow because it’s faster and more compact, at the cost of a slightly different usage.
There are a few possible ways to approach these kinds of issues:
Approach 1: Avoid the type in the first place
As always, we’ll try to follow the “just make it work” advice in here. It’s a perfectly valid solution to just comment out the optimizations and add a // TODO above so that they can be reviewed later. You might be asking for too much complexity in your plugin system; limiting yourself to the functionality in std may be more than enough for now. You’ll now see that it’s always possible to fix this properly. It just might be too much effort at the moment.
In Value’s specific case, it seems like removing the optimizations that are giving us trouble is the easiest way to fix this problem. And it would, if removing code wasn’t also tricky when the optimizations aren’t performed transparently to the hash map functionality. After trying to remove them I eventually gave up because I considered it was getting out of hands with so many changes.
These are 120 errors after attempting to remove the optimizations, most of them about lifetime hell (more about this at the end of the article):

Approach 2: Implement a wrapper
Another possibility is to write a wrapper for halfbrown. Opaque types, for instance, may be used to wrap the functionality of an underlying type that’s not FFI-safe, as I covered in previous articles. This is what abi_stable does in its external_types module for crates like crossbeam or parking_lot.
However, as you may see with the already existing examples, implementing wrappers can be quite a cumbersome task. And even after you’re done you’ll have to keep them up to date, so this will increase your maintainance burden. halfbrown and beef are somewhat complex libraries, so I decided this wasn’t the best choice at that moment for Value. I did use this approach a lot in other cases, so I’ve included an example in a later section.
Approach 3: Re-implement with #[repr(C)] from scratch
Similar to implementing a wrapper, but on steroids. It might seem like overkill, but as far as I know it’s the only choice in some scenarios, because we can make sure the type is as performant as it can get. In Value’s example, the problematic types are part of optimizations, so writing a wrapper for them may have a performance hit and render them useless (e.g., if we used opaque types we would introduce at least a mandatory pointer indirection).
If this part of the project is important enough, or you consider that there’s enough manpower, then it might not be such a bad idea to create a new implementation with your use-case in mind. It’s actually why Tremor’s Value was created in the first place; simd_json::Value wasn’t flexible enough for them, so they decided to define their own version. Same thing could be applied for your plugin system.
Approach 4: Simplifying the type at the FFI boundary
The last idea I came up with was the easiest one: creating a copy of Value meant to be used only for FFI communication, PdkValue:
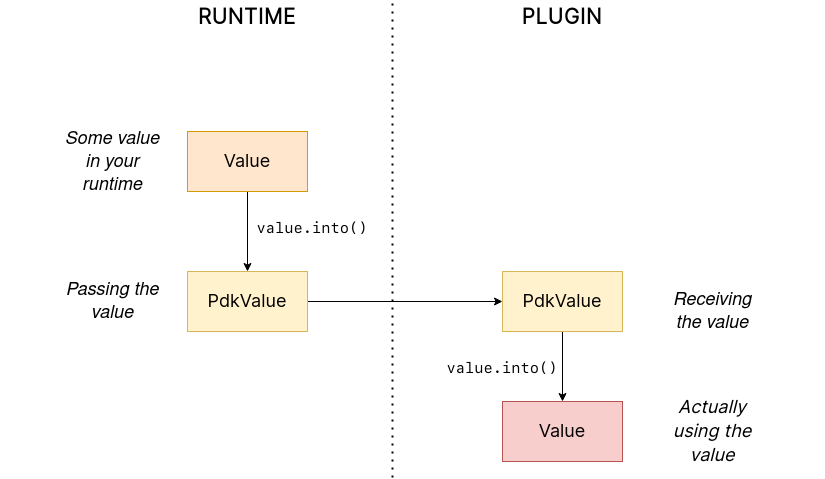
Since it’s a new type, we won’t run into the breaking changes I showed in the Avoid the type in the first place section, and it’s quite easy to implement:
#[repr(C)]
#[derive(StableAbi)]
pub enum PdkValue {
/// Static values (integers, booleans, etc)
Static(StaticNode),
/// String type
String(RString),
/// Array type
Array(RVec<PdkValue>),
/// Object type
Object(RBox<RHashMap<RString, PdkValue>>),
/// A binary type
Bytes(RVec<u8>),
}We don’t need to write any additional methods for the new PdkValue, only its conversions to and from the regular Value. This would be equivalent to, instead of passing a Vec to the interface, replacing it with a *const u8 for the data and a u32 for the length. We’re just simplifying the types at the FFI boundary, and then maybe converting them back for access to the full functionality.
The problem in my case is that these conversions are now $O(n)$ instead of $O(1)$, because I have to iterate the objects and arrays in order to convert its inner values as well:
impl From<Value> for PdkValue {
fn from(original: Value) -> Self {
match original {
// No conversion needed; `StaticNode` implements `StableAbi`
Value::Static(s) => PdkValue::Static(s),
// This conversion is cheap
Value::String(s) => PdkValue::String(s.into()),
// This unfortunately requires iterating the array
Value::Array(a) => {
let a = a.into_iter().map(Into::into).collect();
PdkValue::Array(a)
}
// This unfortunately requires iterating the map and a new
// allocation
Value::Object(m) => {
let m = m.into_iter().map(Into::into).collect();
PdkValue::Object(RBox::new(m))
}
// This conversion is cheap
Value::Bytes(b) => PdkValue::Bytes(conv_u8(b)),
}
}
}
// Same as before, but inversely
impl From<PdkValue> for Value {
fn from(original: PdkValue) -> Self {
match original {
PdkValue::Static(s) => Value::Static(s),
PdkValue::String(s) => Value::String(s.into()),
PdkValue::Array(a) => {
let a = a.into_iter().map(Into::into).collect();
Value::Array(a)
}
PdkValue::Object(m) => {
// No Box dereference move magic with RBox, we call `into_inner`
let m = RBox::into_inner(m);
let m = m
.into_iter()
.map(|Tuple2(k, v)| (k.into(), v.into()))
.collect();
Value::Object(Box::new(m))
}
PdkValue::Bytes(b) => Value::Bytes(conv_u8_inv(b)),
}
}
}And then we can use it like:
// This is implemented in the plugin. It will work because `PdkValue` is
// FFI-safe.
pub extern "C" fn plugin_stuff(value: PdkValue) {
let value = Value::from(value);
value.do_stuff()
}
// This is implemented in the runtime
fn runtime_wrapper(value: Value) {
plugin_stuff(value.into());
}Surprisingly easy to get working! Two problems, though:
-
Usability: the snippet of code above shows that the conversions introduce some noise in our code, as opposed to having a single
#[repr(C)]Value. It could be worse, but it can get annoying when you have manyValues in your runtime and have to pass them to the plugins.This is actually trivial enough to simplify with a macro — perferrably procedural — at the cost of introducing more complexity. We’re currently following “just make it work” so we’ll leave that for the future.
-
Performance: passing the value to the plugin and converting it back in there means we’re iterating the data twice. With experiments that I’ll include in the next article, I found out that these conversions make up 5 to 10% of Tremor’s execution time. Which is less than I expected, but still not good enough for production.
For the first version of the plugin system, this is the solution that I ended up using for Value. Most of the time I spent was just trying the different available approaches, and this one won in simplicity by a huge margin. After being done, I would be able to decide if the performance hit was bad enough, and then maybe switch to a different one. Creating PdkValue wasn’t a big time investment, so it wouldn’t really feel like a waste.
Asynchronous plugins
async functions
I’ve always wanted to avoid communication primitives between plugins and runtime other than plain synchronous calls. But this might be inevitable if your program uses asynchronous programming heavily, which is the case of Tremor. Anyhow, turns out that using async in FFI isn’t that complicated!
In the previous post I introduced the async_ffi crate, which exports FFI-compatible Futures. It’s quite easy to use; here’s an example from the docs:
use async_ffi::{FfiFuture, FutureExt};
#[no_mangle]
pub extern "C" fn work(arg: u32) -> FfiFuture<u32> {
async move {
let ret = do_some_io(arg).await;
do_some_sleep(42).await;
ret
}
.into_ffi()
}The types in async_ffi implement Future, so invoking that function is as easy as usual: just adding .await after the function call.
It’s admittedly a bit ugly to use async move { }.into_ffi() everywhere, specially because it increases the indentation in one level. But that’s something that can be fixed with a procedural macro in the future:
Procedural macro for boilerplate oxalica/async-ffi#12
The only problem I found was that the futures didn’t implement StableAbi, so it wasn’t possible to use them with abi_stable. It took me a while to understand the crate, but it’s nothing a Pull Request can’t fix:
Support for abi_stable oxalica/async-ffi#10
One concern here may be performance. I imagine that it’s not a huge problem because the crate is actualy quite small and only introduces some pointer juggling. I will confirm this in the next post with some benchmarks, though.
Channels
Tremor also needs channels for asynchronous communication. For example, a connector may need to indicate the runtime that the connection has been lost at any point of its execution. We can’t delay that until the next synchronous call from the runtime because we don’t know when that might happen, and we want to keep Tremor low-latency.
We have three options here:
Option 1: Use abi_stable’s alternatives
Turns out abi_stable includes an FFI-safe wrapper for crossbeam. We could just switch the usage of Sender<T> to RSender<T> and that’s it.
Problem: Tremor actually uses asynchronous channels, such as async_std::channel, so it wasn’t as easy as changing to crossbeam. We want to be able to poll for events without blocking the thread.
Option 2: Callbacks
If your use-case is simple enough, callbacks might be sufficient. I experimented a bit with them and it’s a good alternative if you:
- Don’t need to listen for events actively (calling
rx.recv()) - Don’t need to access much data other than the callback’s parameters. Note that it’s a function and not a closure, so you’d need globals, and that can get nasty real quick.
The type definition in the shared crate:
#[repr(C)]
pub struct ConnectorContext {
id: i32,
callback: extern "C" fn(i32),
}The callback definition and the plugin loading in the runtime:
// This will run a few plugins concurrently.
pub fn run() {
// You still have access to some resources in the runtime, but don't
// abuse it!
static COUNT: AtomicI32 = AtomicI32::new(0);
extern "C" fn callback(x: i32) {
println!("raw callback invoked! {x:?}");
COUNT.fetch_add(1, Ordering::Relaxed);
}
let mut handles = Vec::new();
for id in 0..NUM_THREADS {
handles.push(thread::spawn(move || {
let ctx = ConnectorContext { id, callback };
plugin_fn(ctx);
}))
}
for handle in handles {
handle.join().unwrap();
}
println!("Final count: {}", COUNT.load(Ordering::Relaxed));
}The functionality implementation in the plugin:
// This only invokes the callback with its own ID.
pub extern "C" fn plugin_fn(ctx: &ConnectorContext) {
// Asynchronous communication!
thread::spawn(move || {
(ctx.callback)(ctx.id);
});
}You can even wrap the function pointer up so that the usage can remain as sender.send(value):
pub struct Sender<T> {
callback: extern "C" fn(T),
}
impl<T> Sender<T> {
pub fn new(callback: extern "C" fn(T)) -> Self {
Self { callback }
}
pub fn send(&self, t: T) {
(self.callback)(t);
}
}However, the use-cases for this are very limited. If you don’t really need to access anything in the runtime you might as well just have a regular function in the shared crate. And if you need more complex functionality you might be better off with a regular channel.
Option 3: Opaque types
We can resort to opaque types for anything we can’t remove or simplify. This is what I did in order to have asynchronous channels available on the plugins.
The interface in the shared crate, using abi_stable:
#[abi_stable::sabi_trait]
pub trait SenderOpaque: Send {
/// Send a message to the runtime
fn send(&self, reply: Reply) -> BorrowingFfiFuture<'_, RResult<()>>;
}
/// Alias for the FFI-safe sender, boxed
pub type BoxedSender = SenderOpaque_TO<'static, RBox<()>>;The plugin loading in the runtime:
impl SenderOpaque for async_std::channel::Sender<Reply> {
fn send(&self, reply: Reply) -> BorrowingFfiFuture<'_, RResult<()>> {
async move {
self.send(reply)
.await
.map_err(|e| RError::new(Error::from(e)))
.into()
}
.into_ffi()
}
}
fn runtime() {
// Non FFI-safe type
let (tx, rx) = async_std::channel::unbounded();
// Maybe multiple times in different asynchronous tasks
let reply_tx = BoxedSender::from_value(tx, TD_Opaque);
library.plugin(reply_tx);
// Waiting for events
while let Ok(reply) = rx.recv().await {
println!("Got a reply from a plugin: {reply:?}");
}
}The functionality implementation in the plugin:
pub extern "C" fn plugin(sender: BoxedSender) {
// Asynchronous communication!
task::spawn(async move {
sender.send(Reply::Fail).await.unwrap()
});
}Loading plugins
Loading plugins in the runtime was actually the easiest part. abi_stable takes care of most of the work; the only thing that was missing for me is a way to find the plugins. This greatly depends on your program: you may hardcode the location, have them passed as CLI arguments, etc.
In the case of Tremor, we wanted to make it possible to configure the directories where the plugins may be saved. Thus, I introduced a new environment variable TREMOR_PLUGIN_PATH. It’s equivalent to PATH in the sense that the directories are separated by colons.
Once the runtime has a list of what directories may contain plugins, it can look for them recursively with the crate walkdir. It’s highly customizable and remarkably easy to use:
/// Recursively finds all the connector plugins in a directory. It doesn't
/// follow symlinks, and has a sensible maximum depth so that it doesn't get
/// stuck.
pub fn find_recursively(base_dir: &str) -> Vec<ConnectorMod_Ref> {
WalkDir::new(base_dir)
// No symlinks are followed for now
.follow_links(false)
// Adding some safe limits
.max_depth(1000)
.into_iter()
// Ignoring permission errors
.filter_map(Result::ok)
// Only try to load those that look like plugins on the current platform
.filter(|file| {
file.path()
.extension()
.map(|ext| ext == env::consts::DLL_EXTENSION)
.unwrap_or(false)
})
// Try to load the plugins and if successful, add them to the result.
// Not being able to load a plugin shouldn't be fatal because it's very
// likely in some situations. Errors will just be printed to the logs.
.filter_map(|file| match ConnectorMod_Ref::load_from_file(file.path()) {
Ok(plugin) => Some(plugin),
Err(e) => {
log::debug!("Failed to load plugin in '{:?}': {}", file.path(), e);
None
}
})
.collect()
}Separating runtime and interface
So far I’ve been assuming the following (ideal) structure for the plugin system:
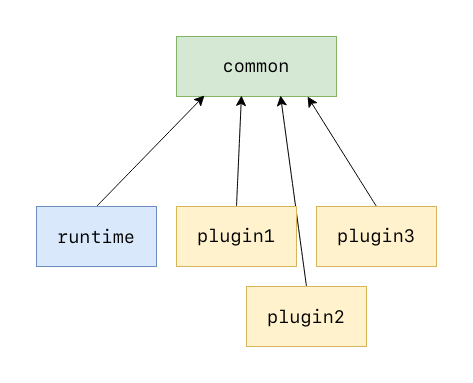
- The
runtimecrate, which loads and runs the plugins. - The
commoncrate, with the interface shared between the plugin and the runtime. - The
plugincrates, with the loadable functionality.
This is essential in order to actually improve compilation times, which is one of the main objectives of our plugin system. There are two ways to look at compilation times:
- For runtime development
- For plugin development
In both cases, we want to compile only either component. If we’re developing a plugin, it makes no sense to be forced to compile the runtime as well, because we aren’t actually changing it. And if we’re working on the runtime, we don’t want to re-compile the functionality from the plugins.
If we just separate the runtime from the plugins, we can achieve the first point. The functionality is now in separate plugin binaries, so the runtime will have considerably lower compilation times.
But we also want to improve plugin compilation times, and if the interface is in the same crate as the runtime, we’ll have to compile both. The shared parts should be written in a separate crate.
The problem is that if you aren’t starting from scratch, it’s very likely that you won’t have a common crate. You’ll just have a single binary crate with everything: runtime, plugins, and common. This is exactly what happened to me with Tremor as well.
For now, I just have the runtime and the interface in the same crate. External plugins then have the entire runtime as a dependency. Which, as I said, is suboptimal, but it works. Moving so much stuff into a separate common crate would mean a ton of conflicts, so I would rather leave it for whenever the first iteration is merged. Here’s the “just make it work” structure for the plugin system:
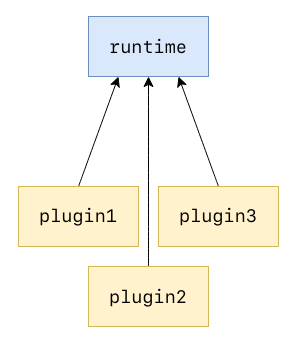
Getting closer to deployment
Preparing the release for the plugin system has always sounded like a quite complicated task. I’ve never wanted to introduce too many changes at once because otherwise it will become very hard to review and merge into the main branch. This is why I decided to schedule the release in four separate iterations:
- Define the new interface and use it internally: the plugin system should be as minimal as possible. The program can be converted to support plugins, but while keeping them in the same binary, for simplicity. The plugin loading functionality can be left as a proof-of-concept for now. Still, this release could maybe include a couple external plugins for testing purposes.
- Separate the runtime from the interface: what I talked about in the previous section can actually be done now. Plugins should be able to depend only on the
commoncrate, rather than on the runtime. We may also run into many Git conflicts while doing this, but it should be a much faster process, since the crate separation is all we have to worry about now. - Actually make the plugins external: since the in-tree plugins are implemented with the new interface, making them actually external should be trivial. It’ll just require re-organizing the repository with the new crates, fixing the build system, and similars.
- Polishing for deployment: last improvements before the release, extensive documentation, evaluating the final results, etc.
Step 2 and 3 can be interchanged as desired, but I thought that the sooner we separate the crates, the better. Plugin development should be much faster after that step for everyone else.
Conclusion
This has been my road to implementing the first version of Tremor’s plugin system. I’m still only on the first step of the schedule, but hey, it works! The next and hopefully last article will cover the final cleaning up, testing and benchmarking required to make it ready for deployment, hopefully in v0.12 :)
I will also work on properly making Value #[repr(C)], instead of also having PdkValue. In retrospect, creating PdkValue was a great decision at that point: these 120 errors I got when trying to make Value #[repr(C)] were related to a nasty bug in RCow’s implementation. Changing from Cow to RCow is broken in some cases because RCow is invariant. For those that don’t know what that means, don’t worry, as I will be releasing another article that explains everything once it’s been fixed. If you’re interested, you can follow this issue in the meanwhile, and hope that you don’t run into it:
lifetimes with R* types break compared to non R* types rodrimati1992/abi_stable_crates#75
After I’m fully done I will also reorganize this series a bit and make it an easier read. I have been writing these articles as I learned how the plugin system could be implemented, so there might be some outdated or repetitive statements in previous articles. If you have any suggestions you can leave them here:
Reorganize rust plugins series once I'm done marioortizmanero/nullderef.com#50
For those interested, I recently gave a quick talk about the whole project in the 2022 LFX Mentorship Showcase. Unfortunately, it was just a 15 minutes presentation, so I couldn’t get into many technical details, but it covers how the whole experience has been so far, and what I’ve learned: